
{kind=link}


As superior analytics and AI proceed to drive enterprise technique, leaders are tasked with constructing versatile, resilient information pipelines that speed up trusted insights. AI pioneer Andrew Ng lately underscored that strong information engineering is foundational to the success of data-centric AI—a method that prioritizes information high quality over mannequin complexity. McKinsey Quarterly’s newest analysis additional forecasts a way forward for “information ubiquity” by 2030, the place enterprise information is seamlessly embedded throughout techniques, processes, and determination factors. For enterprises, the problem now is not only fast deployment; it’s about constructing trusted, iterative processes that guarantee high-quality and actionable information at scale.
Cloudera Information Engineering’s newest model launch on public cloud addresses this rising problem by introducing main enhancements in growth productiveness with enterprise-secured toolings, bringing distant entry to Apache Spark from the practitioner’s most well-liked coding environments. This launch marks a milestone towards Cloudera Information Engineering’s imaginative and prescient of offering one of the best practitioner-centric, production-grade pipelining and orchestration options.
A New Stage of Productiveness with Distant Entry
The brand new Cloudera Information Engineering 1.23 on public cloud spotlights Exterior IDE Connectivity, which allows information engineers to entry Apache Spark clusters and information pipelines immediately from their most well-liked growth environments (e.g., Jupyter, PyCharm, and VS Code). Prolonged information practitioner groups can work of their most well-liked coding environments with out proprietary lock-ins.
Together with Cloudera Information Engineering’s Interactive Classes, information groups can reap the advantages of iterative growth, fostering extra collaborative iterative workflows to drive high quality whereas sustaining strong safety requirements.
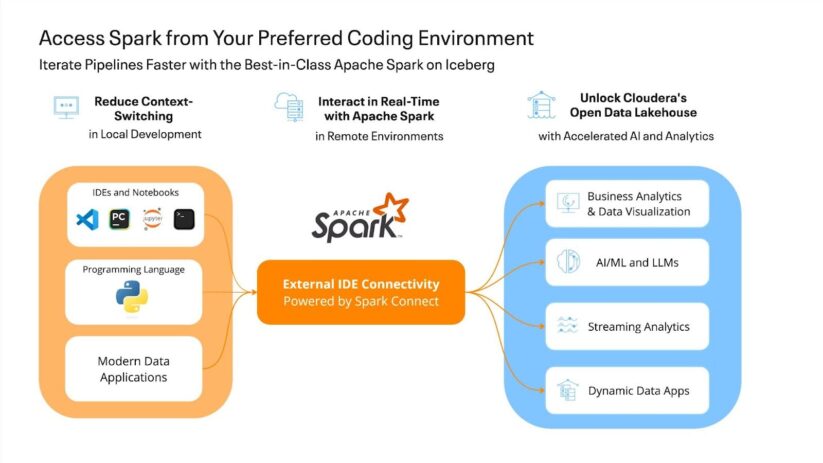
Finest-in-Class Apache Spark on Iceberg
This launch additionally brings new capabilities designed to reinforce cost-effectiveness. Assist for Apache Iceberg 1.5, along with Apache Spark 3.5, delivers higher efficiency and optimized price administration. In Change Information Seize (CDC) use circumstances, superior row-level deletes with Merge-on-Learn enhance question effectivity, lowering useful resource consumption and operational prices.
Why Cloudera Information Engineering?
Cloudera prospects profit from enterprise-secured instruments to construct collaborative sandboxes, empowering information engineers, information scientists, and prolonged information practitioner groups that want insights to drive choices. With 100x extra information below administration in comparison with different cloud-only distributors, Cloudera empowers enterprises to construct open information lakehouses for scalable and safe information administration with moveable analytics throughout hybrid cloud environments.
Prime innovators from monetary, healthcare, and different data-intensive industries depend on Cloudera Information Engineering for a number of causes:
- Safe Information Pipelining Throughout Hybrid Environments: With Apache Spark because the engine, Cloudera Information Engineering gives safe ingestion, seamlessly dealing with information in numerous codecs throughout hybrid clouds to satisfy the numerous wants of recent information pipelines. Powered by built-in platform providers, Cloudera Information Engineering ensures information governance with strong information dealing with and automatic lifecycle lineage monitoring.
- Simplified Workflows and Iterative Collaborations: With Apache Airflow, Cloudera Information Engineering gives API integrations for exterior information instruments like dbt. Interactive Classes and the most recent Exterior IDE Connectivity help fast iterations and collaborations.
- Information Interoperability With Decrease TCO: Cloudera Information Engineering has native help for Apache Iceberg – the main open desk format purpose-built for managing exabyte-scale information lakes and delivering high-performance queries. In contrast to cloud distributors with proprietary engines, Cloudera Information Engineering optimizes price effectivity by leveraging open-source applied sciences and built-in platform providers like Cloudera Observability.
Able to Discover?
Uncover how Cloudera Information Engineering can speed up time-to-value in constructing future-proof trendy information architectures: