
{kind=link}

VAST Knowledge is quietly assembling a single unified platform able to dealing with a variety of HPC, superior analytics, and massive information use instances. At the moment it unveiled a serious replace to its VAST Knowledge Platform engine aimed toward enabling enterprises to run retrieval augmented era (RAG) AI workloads at exabyte scale.
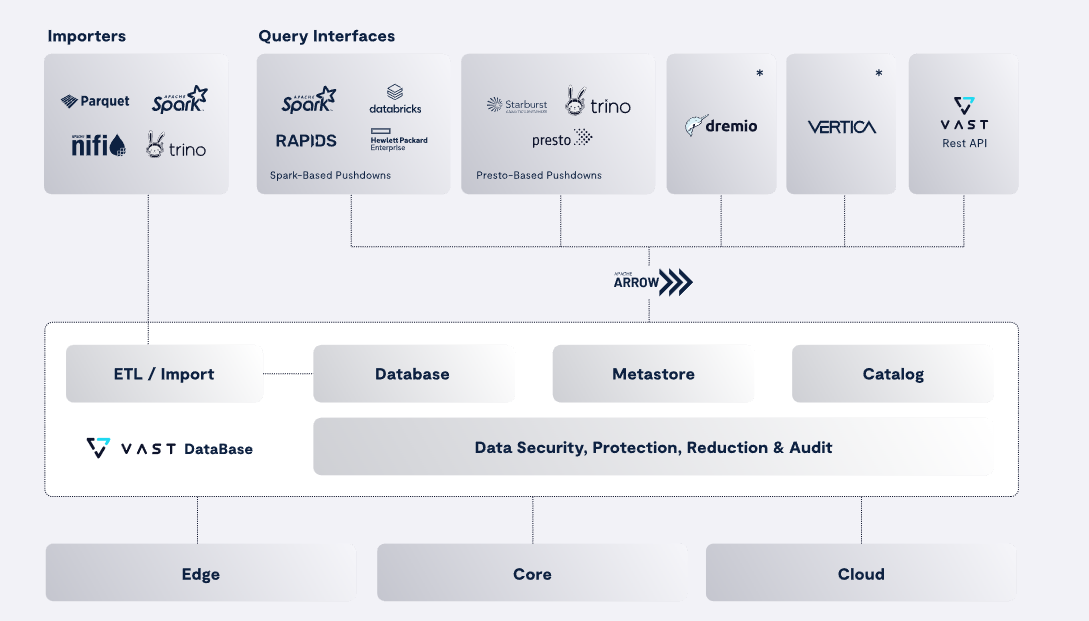
When strong state drives went mainstream and NVMe over Cloth was invented almost a decade in the past, the oldsters who based VAST Knowledge–Renen Hallak, Shachar Fienblit, and Jeff Denworth–sensed a possibility to rearchitect information storage for prime efficiency computing (HPC) on the exabyte stage. As a substitute of making an attempt to scale current cloud-based platforms into the HPC realm, they determined to take a clean-sheet strategy through DASE, which stands for Disaggregated and Shared Every thing.
The primary aspect of the brand new DASE strategy with VAST Knowledge Platform was the VAST DataStore, which supplies massively scalable object and file storage for structured and unstructured information. That was adopted up with DataBase, which features as a desk retailer, offering information lakehouse performance just like Apache Iceberg. The DataEngine supplies the aptitude to execute features on the information, whereas the DataSpace supplies a world namespace for storing, retrieving, and processing information from the cloud to the sting.
In October, VAST Knowledge unveiled the InsightEngine, which is the primary new utility designed to run atop the corporate’s information platform. InsightEngine makes use of Nvidia Inference Microservices (NIMs) from Nvidia to have the ability to set off sure actions when information hits the platform. Then just a few weeks in the past, VAST Knowledge bolstered these current capabilities with assist for block storage and real-time occasion streaming through an Apache Kafka-compatible API.
At the moment, it bolstered the VAST Knowledge platform with three new capabilities, together with assist for vector search and retrieval; serverless triggers and features; and fine-grained entry management. These capabilities will assist the corporate and its platform to serve the rising RAG wants of its clients, says VAST Knowledge VP of Product Aaron Chaisson.
VAST DataBase was created in 2019 as a multi-protocol file and object retailer (Supply: VAST Knowledge)
“We’re mainly extending our database to assist vectors, after which make that accessible for both agentic querying or chatbot querying for individuals,” Chaisson says. “The thought right here was to have the ability to assist enterprise clients actually unlock their information with out having to provide their information to a mannequin builder or fine-tune fashions.”
Enterprise clients like banks, hospitals, and retailers usually have their information in every single place, which makes it exhausting to assemble and use for RAG pipelines. VAST Knowledge’s new triggering perform can assist clients consolidate that information for inference use instances.
“As information hits our information retailer, that may set off an occasion that may name an Nvidia NIM…and considered one of their massive language fashions and their embedding techniques to take that information that we save, and convert that into that vectorized state for AI operations.”
By creating and storing vectors straight within the VAST Knowledge platform, it eliminates the necessity for patrons to make use of a separate vector database, Chaisson says.![]()
“That that enables us to now retailer these vectors at exabyte scale in a single database that spreads throughout our whole system,” he says. “So somewhat than having so as to add servers and reminiscence to scale a database, it could possibly scale to the dimensions of our whole system, which may be lots of and lots of of nodes.”
Maintaining all of this information safe is the purpose of the third announcement, assist for fine-grained entry management by way of row- and column-level permissions. Maintaining all of this throughout the VAST platform offers clients sure safety benefits in comparison with utilizing third-party instruments to handle permissions.
“The problem that traditionally occurs is that once you vectorize your recordsdata, the safety doesn’t include it,” he says. “You may find yourself by accident having someone getting access to the vectors and the chunks of the information who shouldn’t have permission to the supply recordsdata. What occurs now with our answer is for those who change the safety on the file, you alter the safety on the vector, and you make sure that throughout that whole information chain, there’s a single unified atomic safety context, which makes it far safer to satisfy quite a lot of the governance and regulatory compliance challenges that folks have with AI.”
VAST Knowledge plans to point out off its its capabilites on the GTC 2025 convention subsequent week.
Associated Objects:
VAST Knowledge Expands Platform With Block Storage And Actual-Time Occasion Streaming
VAST Appears to be like Inward, Outward for An AI Edge
The VAST Potential for Internet hosting GenAI Workloads, Knowledge