
{kind=link}
It is a visitor put up by Hossein Johari, Lead and Senior Architect at Stifel Monetary Corp, Srinivas Kandi and Ahmad Rawashdeh, Senior Architects at Stifel, in partnership with AWS.
Stifel Monetary Corp, a diversified monetary companies holding firm is increasing its knowledge panorama that requires an orchestration answer able to managing more and more advanced knowledge pipeline operations throughout a number of enterprise domains. Conventional time-based scheduling programs fall brief in addressing the dynamic interdependencies between knowledge merchandise, requires event-driven orchestration. Key challenges embody coordinating cross-domain dependencies, sustaining knowledge consistency throughout enterprise items, assembly stringent SLAs, and scaling successfully as knowledge volumes develop. With out a versatile orchestration answer, these points can result in delayed enterprise operations and insights, elevated operational overhead, and heightened compliance dangers attributable to handbook interventions and inflexible scheduling mechanisms that can’t adapt to evolving enterprise wants.
On this put up, we stroll by way of how Stifel Monetary Corp, in collaboration with AWS ProServe, has addressed these challenges by constructing a modular, event-driven orchestration answer utilizing AWS native companies that allows exact triggering of information pipelines based mostly on dependency satisfaction, supporting close to real-time responsiveness and cross-domain coordination.
Information platform orchestration
Stifel and AWS know-how groups recognized a number of key necessities that will information their answer structure to beat the above listed challenges together with conventional knowledge pipeline orchestration.
Coordinated pipeline execution throughout a number of knowledge domains based mostly on occasions
- The orchestration answer should assist triggering knowledge pipelines throughout a number of enterprise domains based mostly on occasions comparable to knowledge product publication or completion of upstream jobs.
Sensible dependency administration
- The answer ought to intelligently handle pipeline dependencies throughout domains and accounts.
- It should be sure that downstream pipelines anticipate all needed upstream knowledge merchandise, no matter which staff or AWS account owns them.
- Dependency logic needs to be dynamic and adaptable to adjustments in knowledge availability.
Enterprise-aligned configuration
- A no-code structure ought to permit enterprise customers and knowledge homeowners to outline pipeline dependencies and triggers utilizing metadata.
- All adjustments to dependency configurations needs to be version-controlled, traceable, and auditable.
Scalable and versatile structure
- The orchestration answer ought to assist lots of of pipelines throughout a number of domains with out efficiency degradation.
- It needs to be straightforward to onboard new domains, outline new dependencies, and combine with current knowledge mesh parts.
Visibility and monitoring
- Enterprise customers and knowledge homeowners ought to have entry exhibiting pipeline standing, together with success, failure, and progress.
- Alerts and notifications needs to be despatched when points happen, with clear diagnostics to assist speedy decision.
Instance Situation
The next under illustrates a cross-domain knowledge dependency state of affairs, the place an information product in area (D1 and D2) depends on the immediate refresh of information merchandise from different domains, every working on distinct schedules. Upon completion, these upstream knowledge merchandise emit refresh occasions that routinely set off the execution of a dependent downstream pipeline.
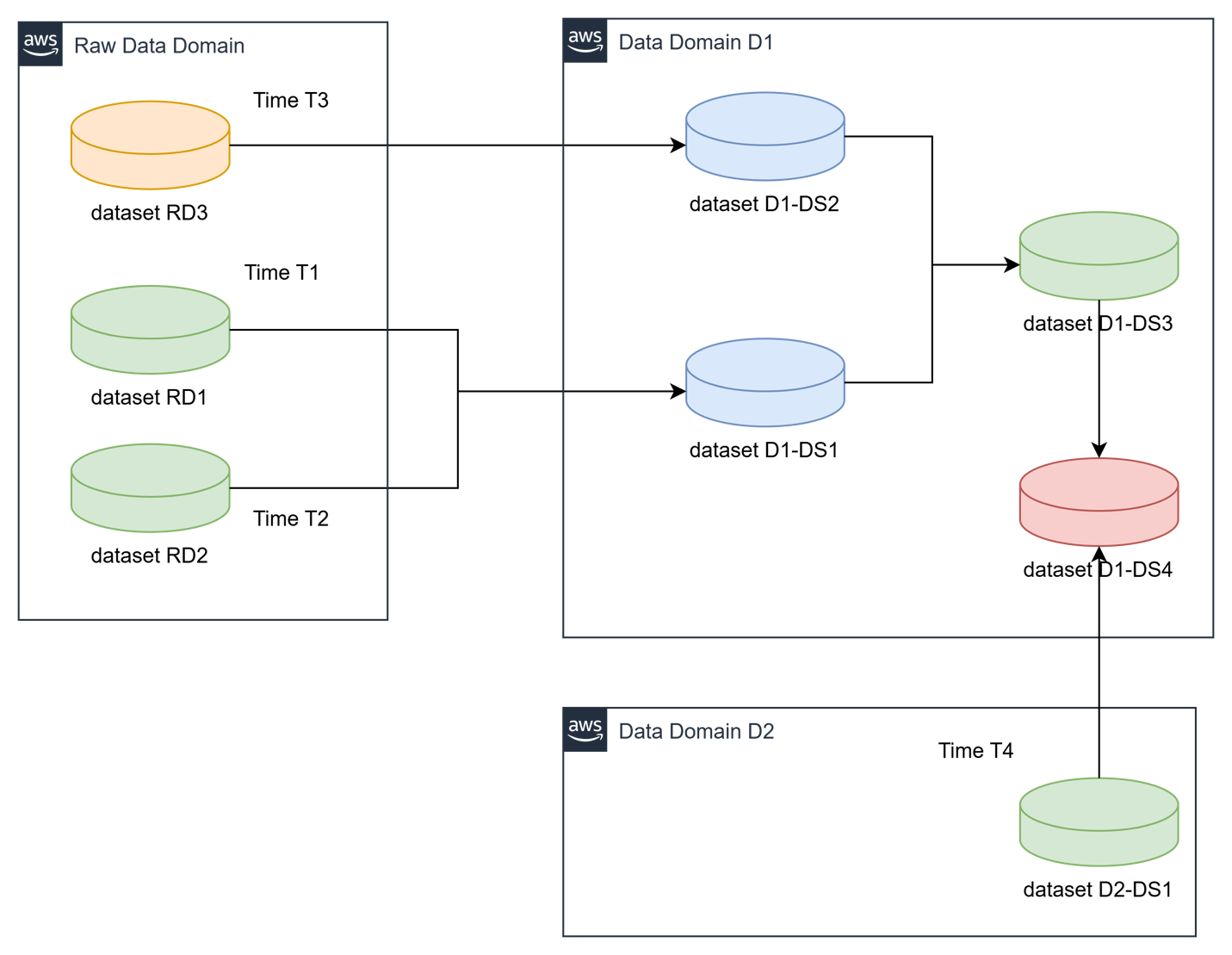
- Dataset DS1 for Area D1 relies on RD1 and RD2 from uncooked knowledge area which will get refreshed at totally different instances T1 and T2
- Dataset DS2 for Area D1 relies on RD3 from uncooked knowledge area which will get refreshed at totally different instances T3
- Dataset DS3 for Area D1 relies on knowledge refresh of datasets DS1 and DS2 from Area D1
- Dataset DS4 for Area D1 relies on datasets DS3 from Area D1 and dataset DS1 from Area D2 which is refreshed at time T4.
Resolution Overview
The orchestration answer includes two essential parts.
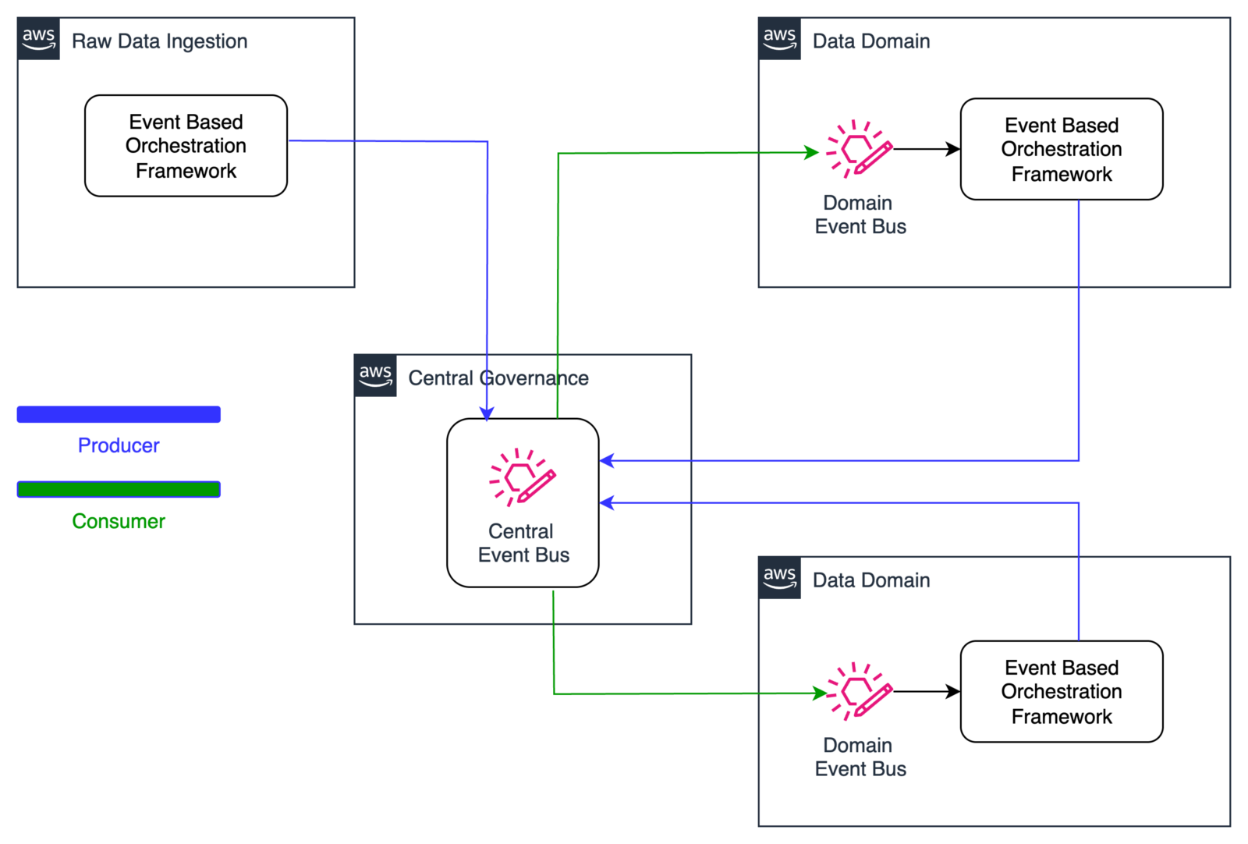
1. Cross account occasion sharing
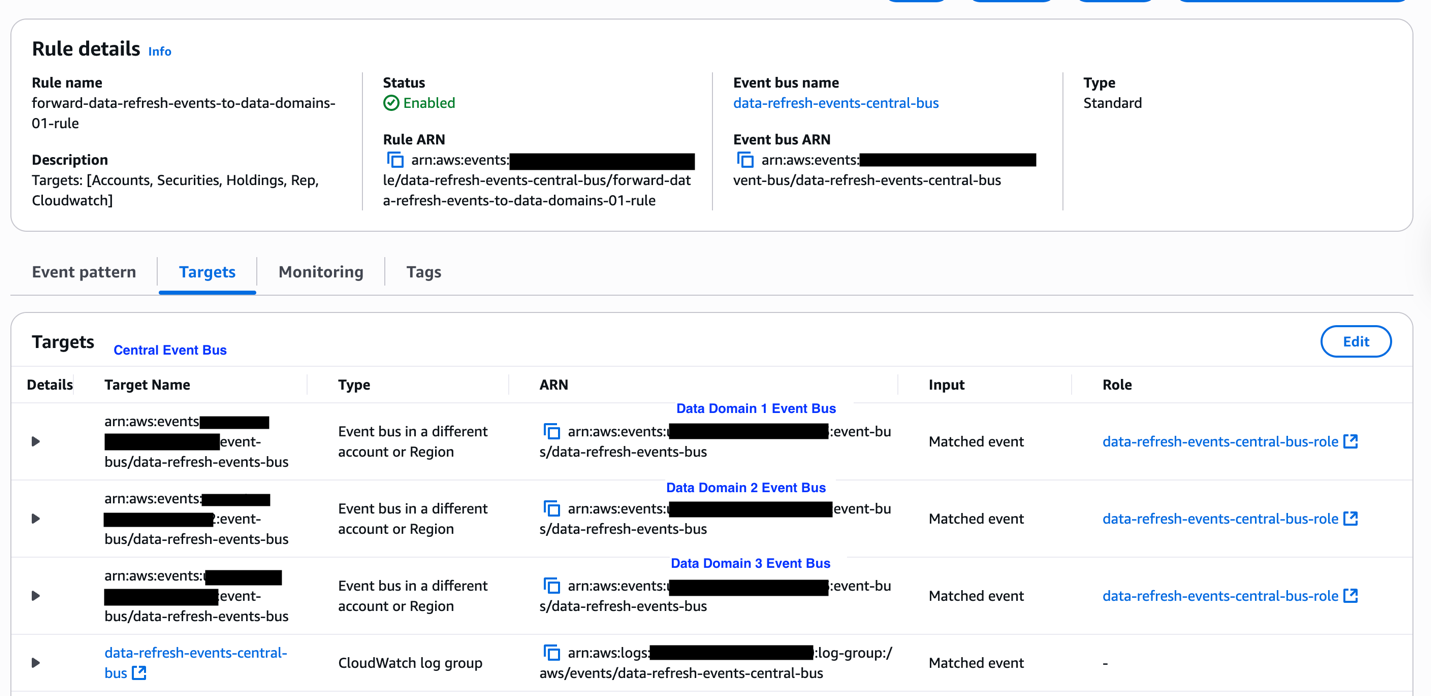
The next diagram illustrates the structure for distributing knowledge refresh occasions throughout domains inside the orchestration answer utilizing Amazon EventBridge. Information producers emit refresh occasions to a centralized occasion bus upon finishing their updates. These occasions are then propagated to all subscribing domains. Every area evaluates incoming occasions in opposition to its pipeline dependency configurations, enabling exact and immediate triggering of downstream knowledge pipelines.
Cross Account Occasion Publish Utilizing Eventbridge
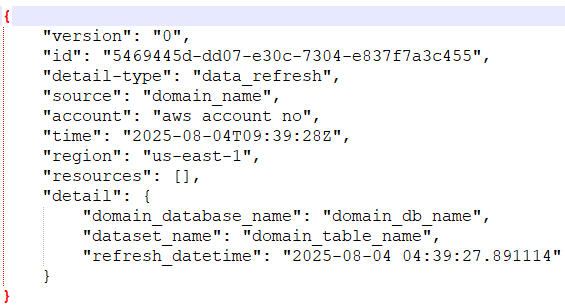
The next snippet reveals the info refresh occasion:
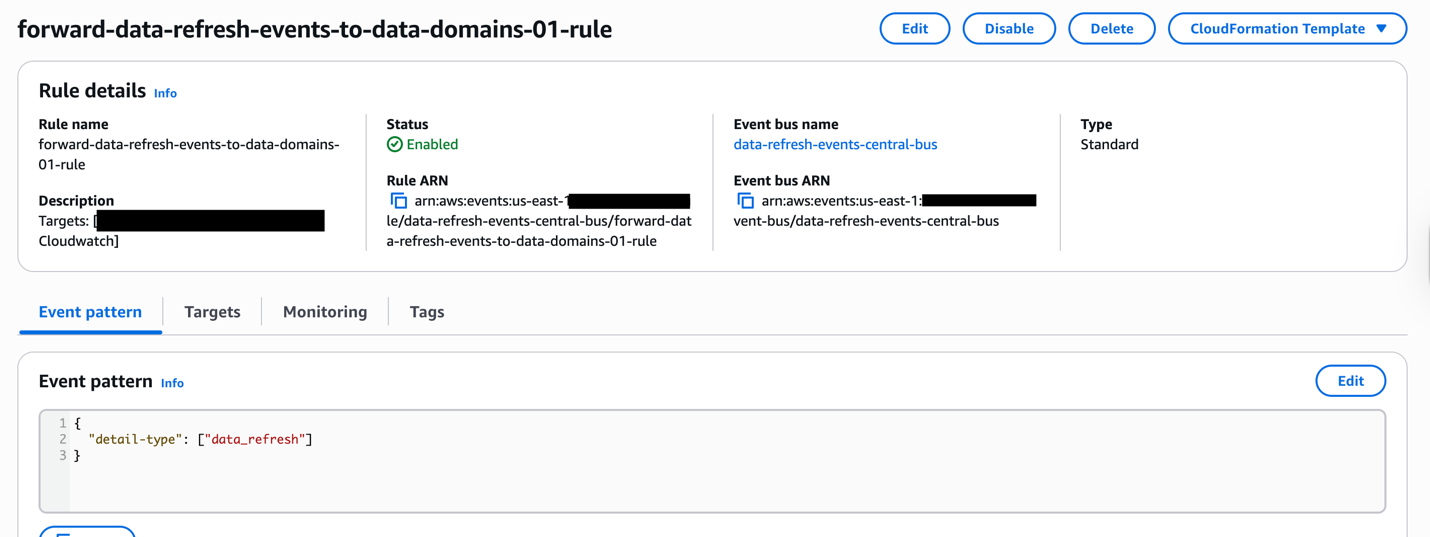
Pattern EventBridge cross account occasion ahead rule.
The next screenshots depicts a pattern knowledge refresh occasion that will likely be broadcasted to shopper knowledge domains.
2. Information Pipeline orchestration
The next diagram describes the technical structure of the orchestration answer utilizing a number of AWS companies comparable to Amazon Eventbridge, Amazon SQS, AWS Lambda, AWS Glue, Amazon SNS and Amazon Aurora.
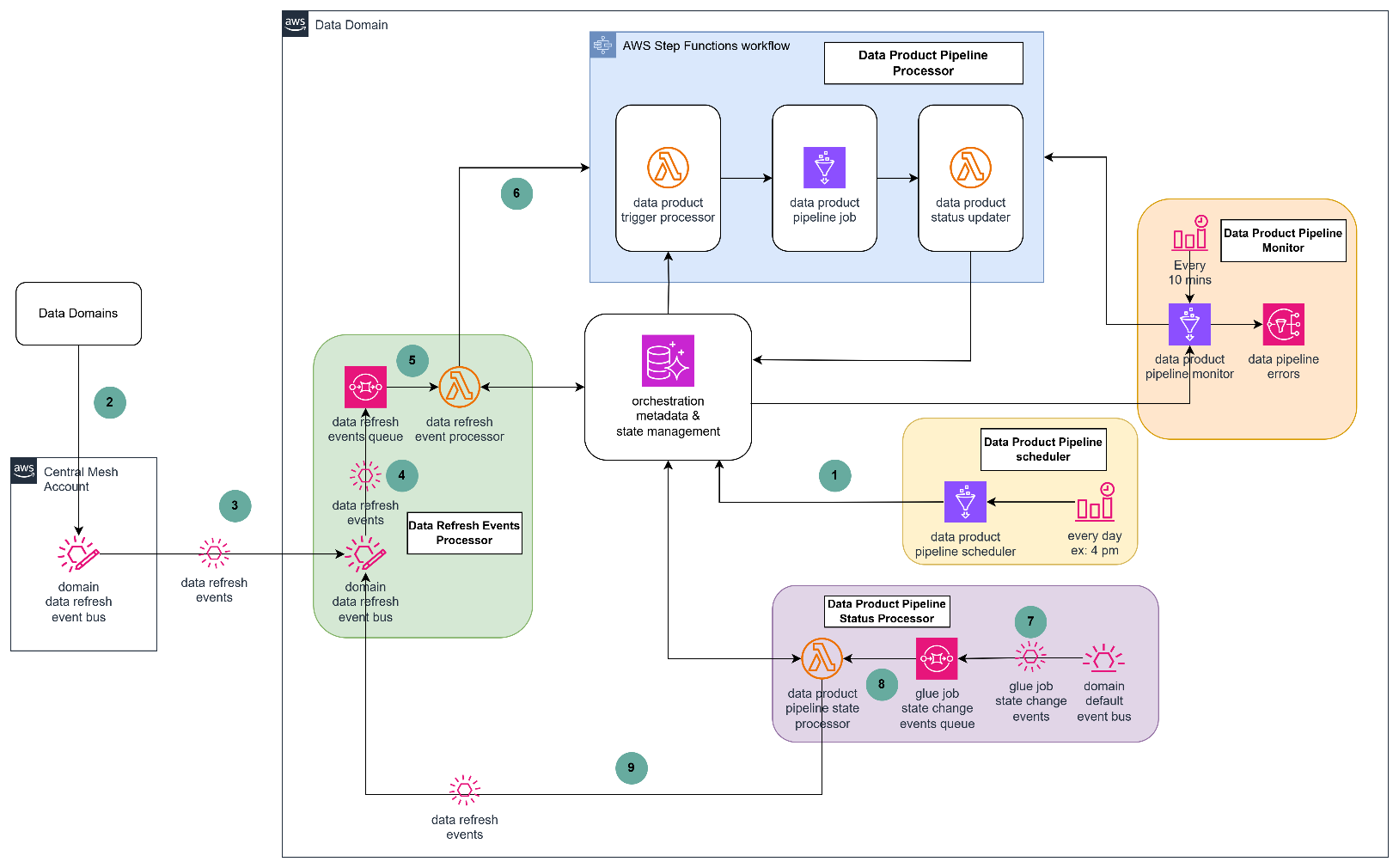
The orchestration answer revolves round 5 core processors.
Information product pipeline scheduler
The scheduler is a day by day scheduled Glue job that finds knowledge merchandise which are due for knowledge refresh based mostly on orchestration metadata and, for every recognized knowledge product, the scheduler retrieves each inner and exterior dependencies and shops them within the orchestration state administration system database tables with a standing of WAITING.
Information refresh occasions processor
Information refresh occasions are emitted from a central occasion bus and routed to domain-specific occasion buses. These area buses ship the occasions to a message queue for asynchronous processing. Any undeliverable occasions are redirected to a dead-letter queue for additional inspection and restoration.
The occasion processor Lambda operate consumes messages from the queue and evaluates whether or not the incoming occasion corresponds to any outlined dependencies inside the area. If a match is discovered, the dependency standing is up to date from WAITING to ARRIVED. The processor additionally checks whether or not all dependencies for a given knowledge product have been happy. In that case, it begins the corresponding pipeline execution workflow by triggering an AWS Step Capabilities state machine.
Information product pipeline processor
Retrieves orchestration metadata to search out the pipeline configuration and related Glue job and parameters for the goal knowledge product. Triggers the Glue job utilizing the retrieved configuration and parameters. This step ensures that the pipeline is launched with the proper context and enter values. It additionally captures the Glue job run Id and updates the info product standing to PROCESSING inside the orchestration state administration database, enabling downstream monitoring and standing monitoring.
Information product pipeline standing processor
Every area’s EventBridge is configured to hear for AWS Glue job state change occasions, that are routed to a message queue for asynchronous processing. A processing operate evaluates incoming job state occasions:
- For profitable job completions, the corresponding pipeline standing is up to date from PROCESSING to COMPLETED within the orchestration state database. If the pipeline is configured to publish downstream occasions, an information refresh occasion is emitted to the central occasion bus.
- For failed jobs, the pipeline standing is up to date from PROCESSING to ERROR, enabling downstream programs to handle exceptions or begin retrying of a failed job.
- Pattern Glue Job state change occasions for profitable completion. The glue job title from the occasion is used to replace the standing of the info product.

Information product pipeline monitor
The pipeline monitoring system operates by way of an EventBridge scheduled set off that prompts each 10 minutes to scan the orchestration state. Throughout this scan, it identifies knowledge merchandise with happy dependencies however pending pipeline execution and initiates these pipelines routinely. When pipeline reruns are needed, the system resets the orchestration state, permitting the monitor to reassess dependencies and set off the suitable pipelines. Any pipeline failures are promptly captured as exception notifications and directed to a devoted notification queue for thorough evaluation and staff alerting.
Orchestration metadata knowledge mannequin
The next diagram describes the reference knowledge mannequin for storing the dependencies and state administration of the info pipelines.
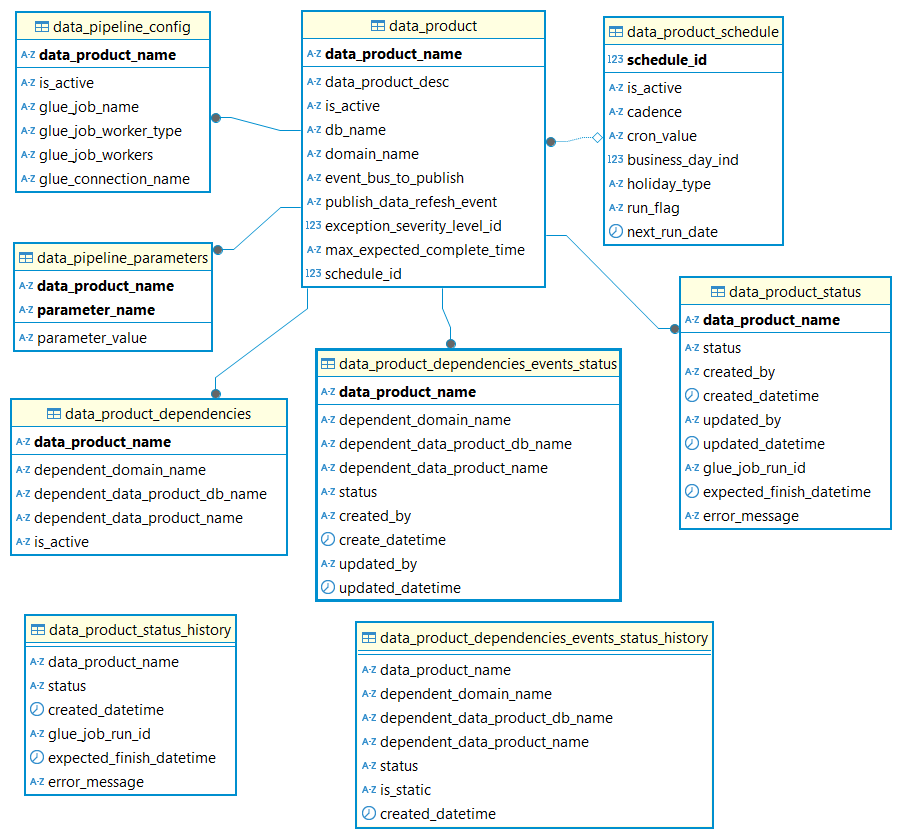
| Desk Title | Description |
| data_product | This desk shops data on the info product and settings such publishing occasion for the info product. |
| data_product_dependencies | This desk shops data on the info product dependencies for each inner and exterior knowledge merchandise. |
| data_product_schedule | This desk shops data on the info product run schedule (Ex: day by day / weekly) |
| data_pipeline_config | This desk shops details about the Glue job used for the info pipeline (ex: Title of the glue job, connections) |
| data_pipeline_parameters | This desk shops the Glue job parameters |
| data_product_status | This desk tracks the execution standing of the info product pipeline, transitioning states from ‘Ready’ to both ‘Full’ or ‘Error’ based mostly on runtime outcomes |
| data_product_dependencies_events_status | This desk shops the standing of information dependencies refresh standing. It’s used to maintain monitor of the dependencies and updates the standing as the info refresh occasions arrive |
| data_product_status_history | This desk shops the historic knowledge of information product knowledge pipeline executions for audit and reporting |
| data_product_dependencies_events_status_history | This desk shops the historic knowledge of information product knowledge dependency standing for audit and reporting |
Consequence
With knowledge pipeline orchestration and use of AWS serverless companies, Stifel was in a position to pace up the info refresh course of by slicing down the lag time related to fastened scheduling of triggering knowledge pipelines as nicely improve the parallelism of executing the info pipelines which was a constraint with on-premises knowledge platform. This strategy gives:
- Scalability by supporting coordination throughout a number of knowledge domains.
- Reliability by way of automated monitoring and backbone of pipeline dependencies.
- Timeliness by making certain pipelines are executed exactly when their stipulations are met.
- Price optimization by leveraging AWS serverless applied sciences Lambda for compute, EventBridge for occasion routing, Aurora Serverless for database operations, and Step Capabilities for workflow orchestration and pay just for precise utilization quite than provisioned capability whereas offering automated scaling to deal with various workloads.
Conclusion
On this put up, we confirmed how a modular, event-driven orchestration answer can successfully handle cross-domain knowledge pipelines. Organizations can discuss with this weblog put up to construct strong knowledge pipeline orchestration avoiding inflexible schedules and dependencies by leveraging event-based triggers.
Particular thanks: This implementation success is a results of shut collaboration between Stifel Monetary management staff (Kyle Broussard Managing Director, Martin Nieuwoudt Director of Information Technique & Analytics) , AWS ProServe, and the AWS account staff. We need to thank Stifel Monetary Executives and the Management Workforce for the robust sponsorship and path.
Concerning the authors