
{kind=link}
Edge computing downtime in industrial IoT environments may be each inconvenient and dear. Programs on the edge require steady operation to take care of enterprise continuity. Whereas AWS IoT Greengrass delivers highly effective edge computing capabilities, attaining true enterprise-grade excessive availability requires extra orchestration. This submit reveals the best way to use Pacemaker, a cluster useful resource supervisor, to construct resilient edge infrastructure with automated failover.
On this walkthrough, you’ll be taught to implement lively/passive and lively/lively excessive availability patterns utilizing Pacemaker with AWS IoT Greengrass, full with automated failover, state replication, and monitoring integration.
The excessive availability problem for edge computing
Conventional cloud functions profit from built-in redundancy and auto-scaling, nevertheless, functions on the sting face distinctive challenges:
- Bodily isolation: Edge units function in distant places with restricted connectivity
- Useful resource constraints: In contrast to cloud environments, edge sources are finite and treasured
- Service criticality: Edge failures can halt bodily operations instantly
- Restoration complexity: Guide intervention at distant websites is dear and gradual
AWS IoT Greengrass addresses many edge computing challenges, however excessive availability requires considerate structure past a single machine deployment.
How Pacemaker enhances AWS IoT Greengrass
Pacemaker helps you construct extremely obtainable AWS IoT Greengrass deployments by way of cluster administration capabilities:
Confirmed reliability
- Utilized in mission-critical environments for over a decade
- Handles advanced failure situations with subtle fencing mechanisms
- Works in each lively/passive and lively/lively configurations
AWS IoT Greengrass-aware useful resource administration
- Screens Greengrass service well being and element states
- Manages shared storage for seamless state switch
- Coordinates failover of dependent companies and community sources
Enterprise-ready integration
- Integrates with present Linux infrastructure administration
- Helps advanced dependency chains and useful resource constraints
- Offers detailed logging and monitoring for compliance necessities
Collectively, these instruments maintain your edge workloads working throughout {hardware} failures or community disruptions.
Structure overview: Excessive availability patterns
AWS IoT Greengrass excessive availability may be applied utilizing two major patterns, every optimized for various use circumstances.
Energetic/Passive configuration: Maximizing information consistency
This mode maximizes information consistency and automatic failover—preferrred for mission-critical functions the place information integrity and repair continuity are paramount. One node runs Greengrass actively whereas the opposite stands prepared in standby mode. A software-based, block-level information replication service like Distributed Replicated Block Gadget (DRBD) ensures immediate state synchronization between nodes, enabling failover with zero information loss and sustaining machine identification.
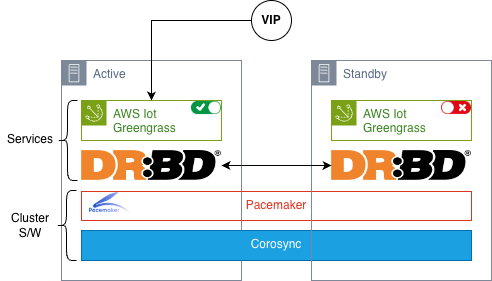
Key advantages:
This configuration ensures full state preservation throughout failover with sub-minute downtime, zero information loss for in-flight transactions and important operations, whereas sustaining machine identification, certificates, and Stream Supervisor persistence seamlessly.
Actual-world use circumstances:
Energetic/Passive configurations are important in situations requiring zero or minimal information loss, reminiscent of in-flight leisure techniques that deal with offline cost processing and battery manufacturing amenities the place manufacturing traces rely upon steady information movement from vital manufacturing sensors and ML mannequin outputs to take care of operational integrity and high quality management.
Energetic/Energetic: Most throughput and scalability
This mode maximizes throughput and offers horizontal scaling for high-volume workloads. A number of unbiased Greengrass cases run concurrently throughout cluster nodes, with clever load balancing distributing work based mostly on node well being and capability. Every node operates with its personal distinctive machine credentials and configurations.
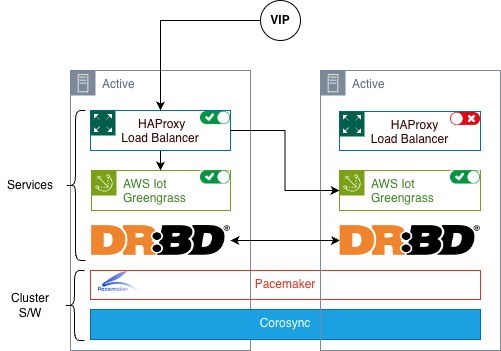
Key advantages:
These configurations allow horizontal scaling for high-throughput situations, enhance useful resource utilization throughout nodes, and supply sleek degradation beneath partial failures.
Actual-world use circumstances:
Energetic/Energetic configurations are perfect for high-volume situations reminiscent of automotive elements manufacturing amenities and large-scale manufacturing operations with a number of manufacturing traces, the place every node handles completely different line segments to offer each redundancy and elevated processing capability for real-time analytics and anomaly detection.
Configuration choice information
Use Energetic/Passive for functions that require zero information loss, shared state, and machine identification preservation. This sample works effectively once you want a single level of management and might settle for failover instances beneath one minute.Use Energetic/Energetic once you want excessive throughput and horizontal scaling. This sample fits functions that may function independently with out shared state, the place load distribution offers operational advantages, and sleek degradation is preferable to finish failover.
implement the answer
The whole playbook, together with detailed configuration examples and testing procedures, is obtainable within the GitHub respository. This offers an Energetic/Passive implementation automation utilizing Ansible you can customise in your particular necessities. Energetic/Energetic setup steps are additionally obtainable in MANUAL-SETUP-GUIDE inside the similar repository.
Setup steps
1. Atmosphere setup
Clone the repository and arrange the event surroundings
2. Configure cluster secrets and techniques
Generate and encrypt cluster credentials utilizing Ansible Vault
This creates `vars/cluster-vault.yml` with encrypted credentials for cluster authentication and DRBD replication.
3. Put together Greengrass credentials
Word: This method is designed for testing and demonstration functions solely.
Obtain Greengrass set up recordsdata from AWS IoT Console.
- Navigate to AWS IoT Core console → Greengrass → Core units
- Click on ‘Arrange one core machine’ → ‘Arrange a tool with installer obtain’
- Title your machine (e.g., ‘greengrass-ha-device’)
- Choose or create a Factor Group
- Obtain each recordsdata and rename them:
- Rename hash-setup.sh to greengrass-setup.sh
- Rename hash.zip to greengrass-certs.zip
- Place recordsdata in `recordsdata/greengrass/` listing
4. Deploy and configure
This may deploy AWS EC2 and mandatory sources to check on AWS.
5. Validate and check
Test cluster standing and optionally, run an automatic failover check.
The automated checks validate useful resource migration, DRBD promotion, and information consistency throughout failover.
Cleanup
This may destroy the sources created by CDK.
Conclusion: Enterprise-ready edge computing
AWS IoT Greengrass and Pacemaker collectively present the excessive availability wanted for mission-critical edge deployments. Through the use of Pacemaker’s cluster administration capabilities, organizations can confidently deploy Greengrass the place reliability is crucial.Whether or not you’re managing industrial management techniques, processing real-time analytics, or orchestrating edge AI workloads, this architectural sample offers the inspiration for resilient, scalable edge computing that your corporation can rely upon.
Subsequent steps
Able to implement enterprise-grade excessive availability in your AWS IoT Greengrass deployments? Right here’s your path ahead:
Repository: sample-greengrass-ha-pacemaker
In regards to the authors
 Yong Ji Yong Ji is a Senior Options Architect at Amazon Internet Companies (AWS), serving to enterprises construct modern cloud-based options. With over 25 years of expertise in cloud structure, analytics and information engineering, Yong brings deep technical experience and a ardour for fixing advanced enterprise challenges. Outdoors of labor, Yong is a passionate desk tennis participant.
Yong Ji Yong Ji is a Senior Options Architect at Amazon Internet Companies (AWS), serving to enterprises construct modern cloud-based options. With over 25 years of expertise in cloud structure, analytics and information engineering, Yong brings deep technical experience and a ardour for fixing advanced enterprise challenges. Outdoors of labor, Yong is a passionate desk tennis participant.
 Siddhant Srivastava Siddhant Srivastava is a Software program Improvement Engineer with AWS IoT Greengrass. He has 3+ years of expertise in edge computing with concentrate on constructing resilient, scalable distributed techniques. Outdoors work, Siddhant participates in soccer leagues and billiards tournaments.
Siddhant Srivastava Siddhant Srivastava is a Software program Improvement Engineer with AWS IoT Greengrass. He has 3+ years of expertise in edge computing with concentrate on constructing resilient, scalable distributed techniques. Outdoors work, Siddhant participates in soccer leagues and billiards tournaments.