
{kind=link}
1. Introduction
The analysis and engineering group at giant have been repeatedly iterating upon Giant Language Fashions (LLMs) with the intention to make them extra educated, general-purpose, and able to becoming into more and more complicated workflows. Over the previous few years, LLMs have progressed from text-only fashions to having multi-modal capabilities; now, we’re more and more seeing a development towards LLMs as a part of compound AI methods. This paradigm envisions an LLM as an integral half of a bigger engineering setting, versus an end-to-end pipeline in and of itself. At Databricks, now we have discovered that this compound AI system mannequin is extra aligned with real-world functions.
To ensure that an LLM to function as half of a bigger system, it must have device use capabilities. Such capabilities allow an LLM to obtain inputs from and produce outputs to exterior sources. Presently, essentially the most generally used device is operate calling, or the flexibility to work together with exterior code corresponding to APIs or customized features. Including this functionality transforms LLMs from remoted textual content processors into integral components of bigger, extra complicated AI methods. Nonetheless, operate calling wants an LLM that may do three issues: interpret person requests precisely, resolve if the request wants exterior code, and assemble a accurately formatted operate name with the fitting arguments.
Think about the next easy instance:
System: You are an AI Assistant who can use operate calls to assist reply the person's queries. You might have entry to a number of climate-related features: get_weather(metropolis, state_abbr), get_timezone(latitude, longitude), get_nearest_station_id...
Consumer: What's the climate in San Francisco?Provided that the LLM has been made conscious of a number of features utilizing the system immediate, it first wants to grasp what the person desires. On this case, the query is pretty easy. Now, it must test if it wants exterior features and if any of the out there features are related. On this case, the get_weather() operate must be used. Even when the LLM has gotten this far, it now must plug within the appropriate arguments. On this case, it’s clear that metropolis=”San Francisco” and state_abbr=”CA”. Due to this fact, it must generate the next output:
Assistant: get_weather("San Francisco", "CA")Now, the compound system constructed on high of the LLM can use this output to make the suitable operate name, get the output, and both return it to the person or feed it again into the LLM to format it properly.
From the above instance, we will see that even a easy question involving operate calling requires the LLM to get many issues proper. However which LLM to make use of? Do all LLMs possess this functionality? Earlier than we will resolve that, we have to first perceive learn how to measure it.
On this weblog put up, we’ll discover operate calling in additional element, beginning with what it’s and learn how to consider it. We’ll concentrate on two distinguished evals: the Berkeley Perform Calling Leaderboard (BFCL) and the Nexus Perform Calling Leaderboard (NFCL). We’ll talk about the particular facets of operate calling that these evals measure in addition to their strengths and limitations. As we are going to see, it’s sadly not a one-size-fits-all technique. To get a holistic image of a mannequin’s potential to carry out operate calling, we have to contemplate a number of elements and analysis strategies.
We’ll share what we have realized from operating these evaluations and talk about the way it will help us select the fitting mannequin for sure duties. We additionally define methods for enhancing an LLM’s operate calling and gear use talents. Particularly, we show that the efficiency of smaller, open supply fashions like DBRX and LLama-3-70b will be elevated via a mixture of cautious prompting and parsing methods, bringing them nearer to and even surpassing GPT-4 high quality in sure facets.
What’s operate calling, and why is it helpful?
Perform calling is a device that permits an LLM to work together with exterior methods utilizing APIs and customized features. Word that “device use” and “operate calling” are sometimes used interchangeably within the literature; operate calling was the primary kind of device launched and stays some of the popularly used instruments to this point. On this weblog, we confer with operate calling as a selected kind of device use. With a purpose to use operate calling, the person first gives the mannequin with a set of obtainable features and their required arguments, sometimes described utilizing JSON schemas. This offers the mannequin the syntactical construction of the operate in addition to descriptions of every argument. When introduced with a person question, the mannequin identifies which (if any) features are related. It then generates the proper operate name, full with the required arguments.
At Databricks, we have noticed two main enterprise use circumstances that leverage operate calling:
- Brokers and sophisticated multi-turn chatbots
- Batch inference function extraction
Brokers
There’s a rising curiosity in “agentic” capabilities for LLMs. Usually talking, an LLM Agent ought to be capable to full a fancy job that will require a number of steps with minimal person intervention. In apply, operate calling is commonly crucial to finish a number of of those steps: as mentioned earlier, it’s the underlying functionality that permits an LLM to work together with current software program infrastructure corresponding to databases, e.g. through REST APIs.
Think about the next state of affairs: You’re a giant enterprise with a considerable amount of monetary projection information in a SQL database. With operate calling, now you can construct a chatbot that has learn entry to that information. An inside person can ask the chatbot a fancy query like “What’s the projected income for our XYZ product on this fiscal 12 months primarily based on final 12 months’s traits?” and the chatbot can use operate calling to request monetary information between two dates which it could then use to offer an correct estimate. Right here’s an instance of what this may occasionally seem like:
Consumer: "What's the projected income for our XYZ product on this fiscal 12 months primarily based on final 12 months's traits?"
Chatbot: To reply this query, I'll must retrieve some monetary information. Let me test our database.
[Function Call: get_financial_data]
Parameters:
- product: "XYZ"
- start_date: "2023-07-01" // Assuming final fiscal 12 months began on this date
- end_date: "2024-06-30" // Present fiscal 12 months finish
- columns: ["last_year_revenue", "growth_rate"]
# this might both be straight executed by designing the chatbot as a compound AI
# system wrapping the mannequin, or manually executed by the person who returns the
# response
[Function Response]
{
"last_year_revenue": 10000000,
"growth_rate": 0.15,
}
Chatbot: Based mostly on the information I've retrieved, I can present you with a projection for XYZ's income this fiscal 12 months:
Final 12 months's income for XYZ was $10 million. The product has proven a development charge of 15% 12 months-over-12 months.
Projecting this pattern ahead, we will estimate that the whole income for XYZ this fiscal 12 months might be roughly $11.5 million. This projection takes into account the present development charge and the efficiency up to now this 12 months.
Would you like me to break down this calculation additional or present any further details about the projection?Batched Function Extraction
Perform calling often refers back to the LLM’s potential to name a operate from user-provided APIs or features. However it additionally means the mannequin should output the operate name within the actual format outlined by the operate’s signature and outline. In apply, that is achieved through the use of JSON as a illustration of the operate. This side will be exploited to resolve a prevalent use case: extracting structured information within the type of JSON objects from unstructured information. We confer with this as “batched function extraction,” and discover that it’s pretty frequent for enterprises to leverage operate calling with the intention to carry out this job. For instance, a authorized agency might use an LLM with function-calling capabilities to course of large collections of contracts to extract key clauses, determine potential dangers, and categorize every doc primarily based on its content material. Utilizing operate calling on this method permits this authorized agency to transform a considerable amount of information into easy JSONs which might be simple to parse and acquire insights from.
2. Analysis Frameworks
The above use circumstances present that by bridging the hole between pure language understanding and sensible, real-world actions, operate calling considerably expands the potential functions of LLMs in enterprise settings. Nonetheless, the query of which LLM to make use of nonetheless stays unanswered. Whereas one would count on most LLMs to be extraordinarily good at these duties, on nearer examination, we discover that they undergo from frequent failure modes rendering them unreliable and tough to make use of, notably in enterprise settings. Due to this fact, like in all issues LLM, dependable evals are of paramount significance.
Regardless of the rising curiosity in operate calling (particularly from enterprise customers), current operate calling evals don’t at all times agree of their format or outcomes. Due to this fact, evaluating operate calling correctly is non-trivial and requires combining a number of evals and extra importantly, understanding each’s strengths and weaknesses. For this weblog, we are going to concentrate on easy, single-turn operate calling and leverage the two most well-liked evals: Berkeley Perform Calling Leaderboard (BFCL) and Nexus Perform Calling Leaderboard (NFCL).
Berkeley Perform Calling Leaderboard
The Berkeley Perform Calling Leaderboard (BFCL) is a well-liked public function-calling eval that’s stored up-to-date with the most recent mannequin releases. It’s created and maintained by the creators of Gorilla-openfunctions-v2, an OSS mannequin constructed for operate calling. Regardless of some limitations, BFCL is a wonderful analysis framework; a excessive rating on its leaderboard usually signifies sturdy function-calling capabilities. As described on this weblog, the eval consists of the next classes. (Word that BFCL additionally accommodates take a look at circumstances with REST APIs and likewise features in several languages. However the overwhelming majority of checks are in Python which is the subset that we contemplate.)
- Easy Perform accommodates the only format: the person gives a single operate description, and the question solely requires that operate to be referred to as.
- A number of Perform is barely more durable, provided that the person gives 2-4 operate descriptions and the mannequin wants to pick out one of the best operate amongst them to invoke with the intention to reply the question.
- Parallel Perform requires invoking a number of operate calls in parallel with one person question. Like Easy Perform, the LLM is given solely a single operate description.
- Parallel A number of Perform is the mix of Parallel and A number of. The mannequin is supplied with a number of operate descriptions, and every of them might have to be invoked zero or a number of instances.
- Relevance Detection consists purely of eventualities the place not one of the offered features are related, and the mannequin shouldn’t invoke any of them.
One may also view these classes from the lens of what abilities it calls for of the mannequin:
- Easy merely wants the mannequin to generate the proper arguments primarily based on the question.
- A number of requires that the mannequin be capable to select the proper operate along with selecting its arguments.
- Parallel requires that the mannequin resolve what number of instances it must invoke the given operate and what arguments it wants for every invocation.
- Parallel A number of checks if the mannequin possesses the entire above abilities.
- Relevance Detection checks if the mannequin is ready to discern when it wants to make use of operate calling and when to not. Nonetheless, Relevance Detection solely accommodates examples the place not one of the features are related. Due to this fact, a mannequin that’s unable to ever carry out operate calling would seemingly rating 100% on it. Nonetheless, given {that a} mannequin performs effectively within the different classes, it turns into a particularly precious eval. This as soon as once more underscores the significance of understanding these evals effectively and viewing them holistically.
Every of the above classes will be evaluated by checking the Summary Syntax Tree (AST) or truly executing the operate name. The AST analysis first constructs the summary syntax tree of the operate name, then extracts the arguments and checks in the event that they match the bottom fact’s potential solutions. (Footnote: For extra particulars confer with: https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html#bfcl)
We discovered that the AST analysis accuracy correlates effectively with the Executable analysis and, due to this fact, solely thought-about AST.
| Strengths | Weaknesses |
|---|---|
| BFCL is pretty numerous and has a number of classes in every class. | The reference implementation applies bespoke parsing for a number of fashions which makes it tough to match pretty throughout fashions (Word: in our implementation, we normalize the parsing throughout fashions to solely embody minimal parsing of the mannequin’s output.) |
| Broadly accepted locally. | A number of classes in BFCL are far too simple and never consultant of real-world use circumstances. Classes like easy and a number of look like saturated and we consider that a lot of the greatest fashions have already crossed the noise ceiling right here. |
| Relevance detection is a vital functionality, notably in real-world functions. |
Nexus Perform Calling Leaderboard
The Nexus Perform Calling Leaderboard (NFCL) can also be a single flip operate calling eval; not like BFCL, it doesn’t embody relevance detection. Nonetheless, it has a number of different options that make it an efficient eval for enterprise operate calling. It’s from the creators of the NexusRaven-v2 which is an OSS mannequin geared toward operate calling. Whereas the NFCL experiences that it outperforms even GPT-4, it solely will get 68.06% on BFCL. This discrepancy as soon as once more reveals the significance of understanding what the eval numbers on a selected benchmark imply for a selected software.
The NFCL classes are cut up primarily based on the supply of their APIs slightly than the type of analysis. Nonetheless, in addition they differ in problem, as we describe beneath.
- NVD Library: The queries on this class are primarily based on the 2 search APIs from the Nationwide Vulnerability Database: searchCVE and searchCPE. Since there are solely two APIs to select from, it is a comparatively simple job that solely requires calling one in every of them. The complexity arises from the truth that every operate has round 30 arguments.
- VirusTotal: These are primarily based on the VirusTotal APIs that are used to research suspicious recordsdata and URLs. There are 12 APIs however they’re easier than NVD. Due to this fact, fashions sometimes rating barely greater on VirusTotal than NVD. VirusTotal nonetheless requires solely a single operate name.
- OTX: These are primarily based on the Open Menace Change APIs. There are 9 very simple APIs and that is often the class the place most fashions rating the very best.
- Locations: These are primarily based on a set of APIs which might be associated to querying particulars about areas. Whereas there are solely 7 pretty easy features, the questions require nested operate calls (eg., fun1(fun2(fun3(args))) ) which makes it tough for many fashions. Whereas a couple of of the questions require just one operate name, many require nesting of as much as 7 features.
- Local weather API: Because the title suggests, that is primarily based on APIs used to retrieve local weather information. Once more, whereas there are solely 9 easy features, they usually require a number of parallel calls and nested calls, making this benchmark fairly tough for many fashions.
- VirusTotal Nested: That is primarily based on the identical APIs because the VirusTotal benchmark, however the questions all require nested operate calls to be answered. This is likely one of the hardest benchmarks, primarily as a result of most fashions weren’t designed to output nested operate calls.
- NVD Nested: That is primarily based on the identical APIs because the NVD benchmark, however the questions require nested operate calls to be answered. Not one of the fashions now we have examined had been capable of rating greater than 10% on this benchmark.
Word that whereas we confer with the above classes as involving APIs, they’re applied utilizing static dummy Python operate definitions whose signatures are primarily based on real-world APIs. Beneath the BFCL taxonomy, NVD, VirustTotal and OTX classes could be labeled as A number of Perform however with extra candidate features to select from. The parallel examples in Local weather could be categorized as Parallel Perform, whereas the nested examples within the remaining classes wouldn’t have an equal. In reality, nested operate calls are a considerably uncommon eval since they’re sometimes dealt with via multi-turn interactions within the function-calling world. This additionally explains why most fashions, together with GPT-4, battle with them. Along with seemingly being out of distribution from the mannequin’s coaching information, the LLM should plan the order of operate invocations and plug them into the proper argument of the later operate calls. We discover that regardless of not being consultant of typical use circumstances, it’s a helpful eval because it checks each planning and structured output era whereas being much less inclined to eval overfitting.
Scoring for NFCL is predicated purely on string matching on the ultimate operate name generated by the mannequin. Whereas this isn’t preferrred, we discover that it hardly ever, if in any respect, results in false positives.
| Strengths | Weaknesses |
|---|---|
| Apart from OTX, not one of the classes look like exhibiting indicators of saturation and sometimes reveal a major hole between fashions whose function-calling capabilities are anticipated to be completely different. | Most function-calling implementations confer with the OpenAI spec; due to this fact, they’re unlikely to resolve the nested classes with out breaking it down right into a multi-turn interplay. |
| The more durable classes requiring nested and parallel calls are nonetheless difficult, even for fashions like GPT-4. We consider that whereas prospects might not use this functionality straight, it’s consultant of the mannequin’s potential to plan and execute which is crucial for complicated real-world functions. | The scoring is predicated on actual string matching of the operate calls and could also be resulting in false negatives. |
| A number of the operate descriptions are missing and will be improved. Moreover, a number of of them are atypical in that they’ve numerous arguments or don’t have any required arguments. | |
| Not one of the examples take a look at relevance detection. |
3. Outcomes from operating the evals
With a purpose to make a good comparability throughout completely different fashions, we determined to run the evals ourselves with some minor modifications. These adjustments had been primarily made to maintain the prompting and parsing uniform throughout fashions.
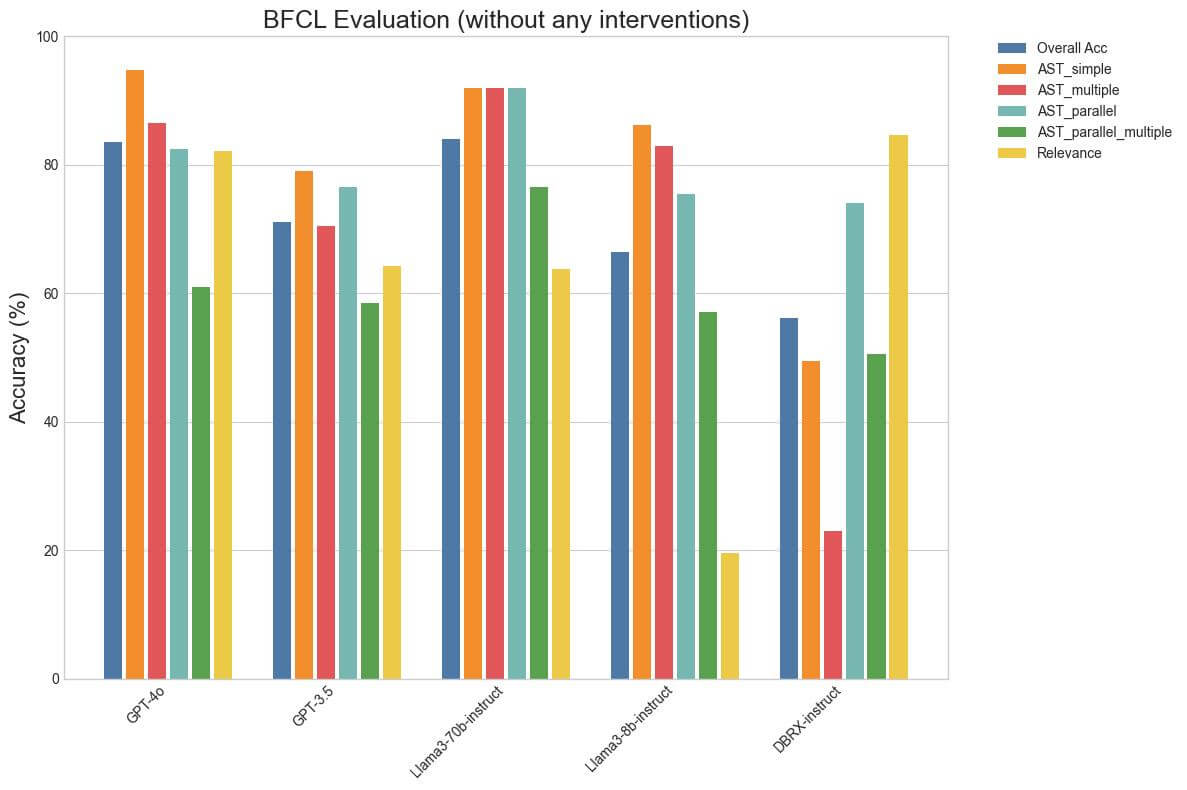
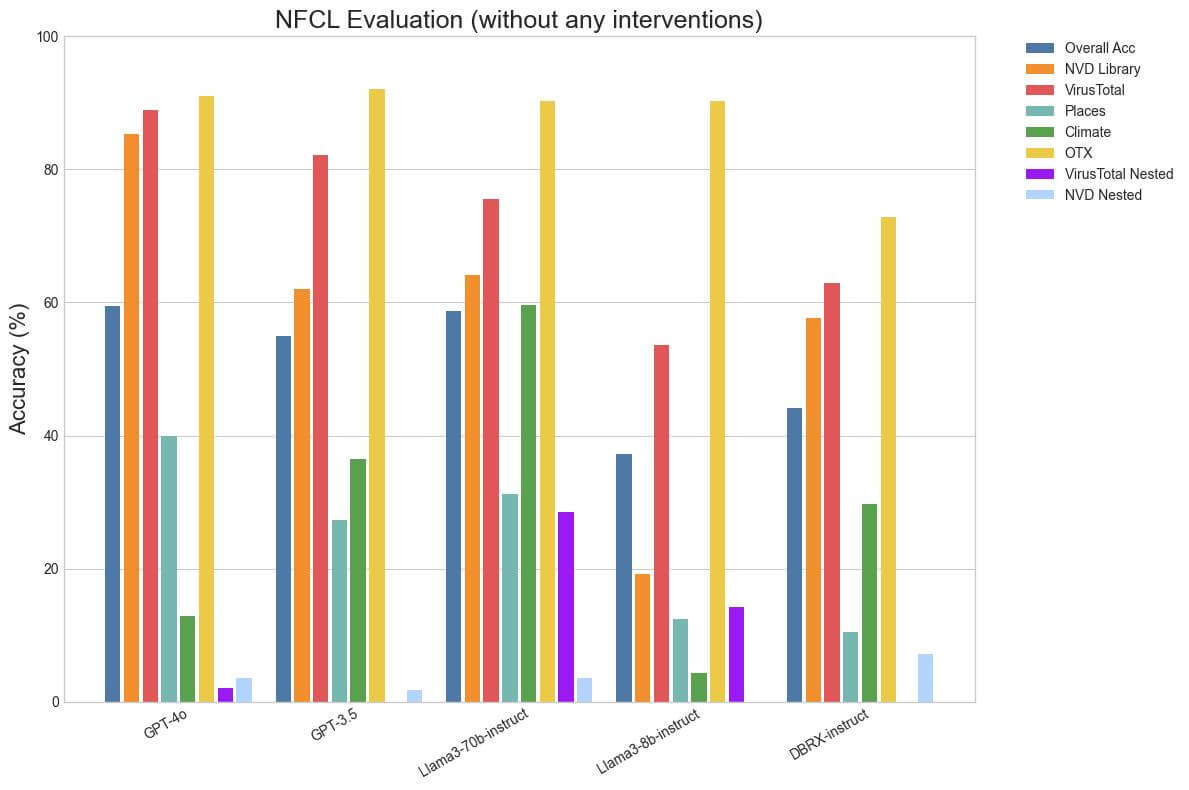
We discovered that evaluating even on publicly out there benchmarks is typically nuanced because the conduct can range wildly with completely different era kwargs. For instance, we discover that accuracy can range as a lot as 10% in some classes of BFCL when producing with Temperature 0.0 vs Temperature 0.7. Since function-calling is a reasonably programmatic job, we discover that utilizing Temperature 0.0 often ends in one of the best efficiency throughout fashions. We made the choice to incorporate the operate definitions and descriptions within the system immediate as repeating them in every person immediate would incur a a lot greater token value in multi-turn conversations. We additionally used the identical minimal parsing throughout fashions in our implementations for each NFCL and BFCL. Word that the DBRX-instruct numbers that we report are decrease than that from the publicly hosted leaderboard whereas the numbers for the opposite fashions are greater. It is because the general public leaderboard makes use of Temperature 0.7 and bespoke parsing for DBRX.
We discover that the outcomes on NFCL with none adjustments align with the anticipated ordering, in that GPT-4o is one of the best in most classes, adopted carefully by Llama3-70b-instruct, then GPT-3.5 after which DBRX-instruct. Llama3-70b-instruct closes the hole to GPT-4o on Local weather and Locations, seemingly as a result of they require nested calls. Considerably surprisingly, DBRX-instruct performs one of the best on NVD Nested regardless of not being educated explicitly for function-calling. We suspect that it’s because it’s not biased towards nested operate calls and easily solves it as a programming train. BFCL reveals some indicators of saturation, in that Llama3-70b-instruct outperforms GPT-4o in nearly each class aside from Relevance Detection, though the latter has seemingly been educated explicitly for function-calling because it helps device use. In reality, LLaMa-3-8b-instruct is surprisingly near GPT-4 on a number of BFCL classes regardless of being a clearly inferior mannequin. We posit {that a} excessive rating on BFCL is a crucial, slightly than ample, situation to be good at operate calling. Low scores point out {that a} mannequin clearly struggles with operate calling whereas a excessive rating doesn’t assure {that a} mannequin is best at operate calling.
4. Bettering Perform-calling Efficiency
As soon as now we have a dependable technique to consider a functionality and know learn how to interpret the outcomes, the apparent subsequent step is to try to enhance these outcomes. We discovered that one of many keys to unlocking a mannequin’s function-calling talents is specifying an in depth system immediate that offers the mannequin the flexibility to cause earlier than making a call on which operate to name, if any. Additional, directing it to construction its outputs utilizing XML tags and a considerably strict format makes parsing the operate name simple and dependable. This eliminates the necessity for bespoke parsing strategies for various fashions and functions.
One other key factor is making certain that the mannequin is given entry to the small print of the operate, its arguments and their information sorts in an efficient format. Guaranteeing that every argument has a knowledge kind and a transparent description helps elevate efficiency. Few-shot examples of anticipated mannequin conduct are notably efficient at guiding the mannequin to judge the relevance of the handed features and discouraging the mannequin from hallucinating features. In our immediate, we used few-shot examples to information the mannequin to undergo every of the offered features one-by-one and consider whether or not they’re related to the duty earlier than deciding which operate to name.

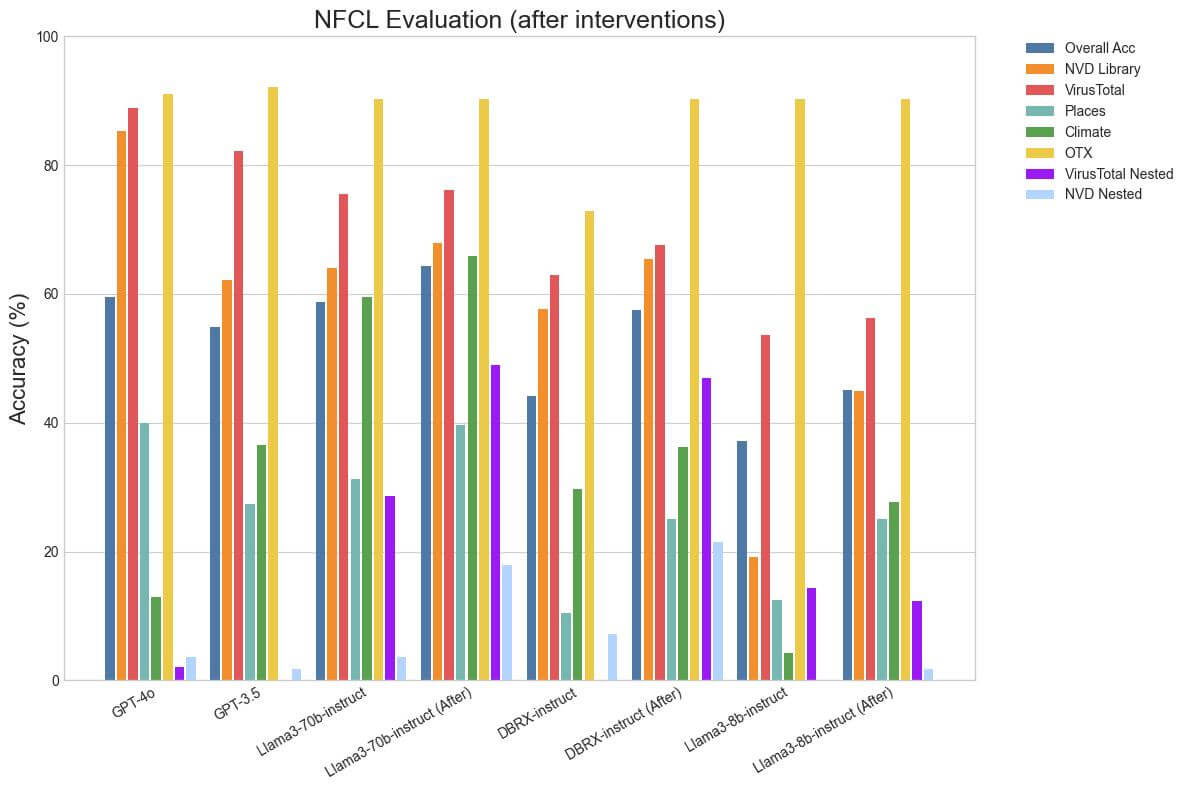
With this method, we had been capable of improve the Relevance Detection accuracy of Llama3-70b-instruct from 63.75% to 75.41% and Llama3-8b-instruct from 19.58% to 78.33%. There are a few counterintuitive outcomes right here: the relevance detection efficiency of Llama3-8b-instruct is greater than the 70b variant! Additionally, the efficiency of DBRX-instruct truly dropped from 84.58% to 77.08%. The explanation for this is because of a limitation in the way in which relevance detection is applied. Since all of the take a look at circumstances solely include irrelevant features, a mannequin that’s poor at function-calling and calls features incorrectly and even fails to ever name a operate will do exceptionally effectively on this class. Due to this fact, it may be deceptive to view this quantity exterior of the context of its general efficiency. The excessive relevance detection accuracy of DBRX-instruct earlier than our adjustments is as a result of its outputs had been usually structurally flawed and due to this fact its general function-calling efficiency was poor.
The final instructions in our system immediate seem like this:
Please use your individual judgment as to whether or not or not it's best to name a operate. In specific, you could comply with these guiding ideas:
1. You might assume the person has applied the operate themselves.
2. You might assume the person will name the operate on their very own. You must NOT ask the person to name the operate and let you recognize the outcome; they'll do that on their very own. You simply want to go the title and arguments.
3. By no means name a operate twice with the identical arguments. Do not repeat your operate calls!
4. If none of the features are related to the person's query, DO NOT MAKE any pointless operate calls.
5. Don't assume entry to any features that aren't listed on this immediate, irrespective of how easy. Don't assume entry to a code interpretor both. DO NOT MAKE UP FUNCTIONS.
You may solely name features in accordance with the next formatting guidelines:
Rule 1: All of the features you will have entry to are contained inside {tool_list_start}{tool_list_end} XML tags. You can not use any features that aren't listed between these tags.
Rule 2: For every operate name, output JSON which conforms to the schema of the operate. You need to wrap the operate name in {tool_call_start}[...list of tool calls...]{tool_call_end} XML tags. Every name might be a JSON object with the keys "title" and "arguments". The "title" key will include the title of the operate you're calling, and the "arguments" key will include the arguments you're passing to the operate as a JSON object. The highest stage construction is a listing of those objects. YOU MUST OUTPUT VALID JSON BETWEEN THE {tool_call_start} AND {tool_call_end} TAGS!
Rule 3: If person decides to run the operate, they'll output the results of the operate name within the following question. If it solutions the person's query, it's best to incorporate the output of the operate in your following message.We additionally specified that the mannequin makes use of the <considering> tag to generate the rationale for the operate name whereas specifying the ultimate operate name inside <tool_call> tags.
Supposed the features out there to you are:
<instruments>
[{'type': 'function', 'function': {'name': 'determine_body_mass_index', 'description': 'Calculate body mass index given weight and height.', 'parameters': {'type': 'object', 'properties': {'weight': {'type': 'number', 'description': 'Weight of the individual in kilograms. This is a float type value.', 'format': 'float'}, 'height': {'type': 'number', 'description': 'Height of the individual in meters. This is a float type value.', 'format': 'float'}}, 'required': ['weight', 'height']}}}]
[{'type': 'function', 'function': {'name': 'math_prod', 'description': 'Compute the product of all numbers in a list.', 'parameters': {'type': 'object', 'properties': {'numbers': {'type': 'array', 'items': {'type': 'number'}, 'description': 'The list of numbers to be added up.'}, 'decimal_places': {'type': 'integer', 'description': 'The number of decimal places to round to. Default is 2.'}}, 'required': ['numbers']}}}]
[{'type': 'function', 'function': {'name': 'distance_calculator_calculate', 'description': 'Calculate the distance between two geographical coordinates.', 'parameters': {'type': 'object', 'properties': {'coordinate_1': {'type': 'array', 'items': {'type': 'number'}, 'description': 'The first coordinate, a pair of latitude and longitude.'}, 'coordinate_2': {'type': 'array', 'items': {'type': 'number'}, 'description': 'The second coordinate, a pair of latitude and longitude.'}}, 'required': ['coordinate_1', 'coordinate_2']}}}]
</instruments>
And the person asks:
Query: What is the present time in New York?
Then it's best to reply with:
<considering>
Let's begin with a listing of features I've entry to:
- determine_body_mass_index: since this operate is just not related to getting the present time, I can't name it.
- math_prod: since this operate is just not related to getting the present time, I can't name it.
- distance_calculator_calculate: since this operate is just not related to getting the present time, I can't name it.
Not one of the out there features, [determine_body_mass_index, math_prod, distance_calculator] are pertinent to the given question. Please test when you neglected any related features.
As a Giant Language Mannequin, with out entry to the suitable instruments, I'm unable to supply the present time in New York.
Whereas the precise system immediate that we used will not be appropriate for all functions and all fashions, the guiding ideas can be utilized to tailor it for particular use circumstances. For instance, with Llama-3-70b-instruct we used an abridged model of our full system immediate which skipped the few-shot examples and omitted a few of the extra verbose directions. We’d additionally like to emphasise that LLMs will be fairly delicate to indentation and we encourage utilizing markdown, capitalization and indentation rigorously.
We computed an mixture metric by averaging throughout the subcategories in BFCL and NFCL whereas dropping the best classes (Easy, OTX). We additionally ignored the Local weather column, because it weights the nested operate calling potential too extremely. Lastly, we upweighted relevance detection since we discovered it notably pertinent to the flexibility of fashions to carry out operate calling within the wild.
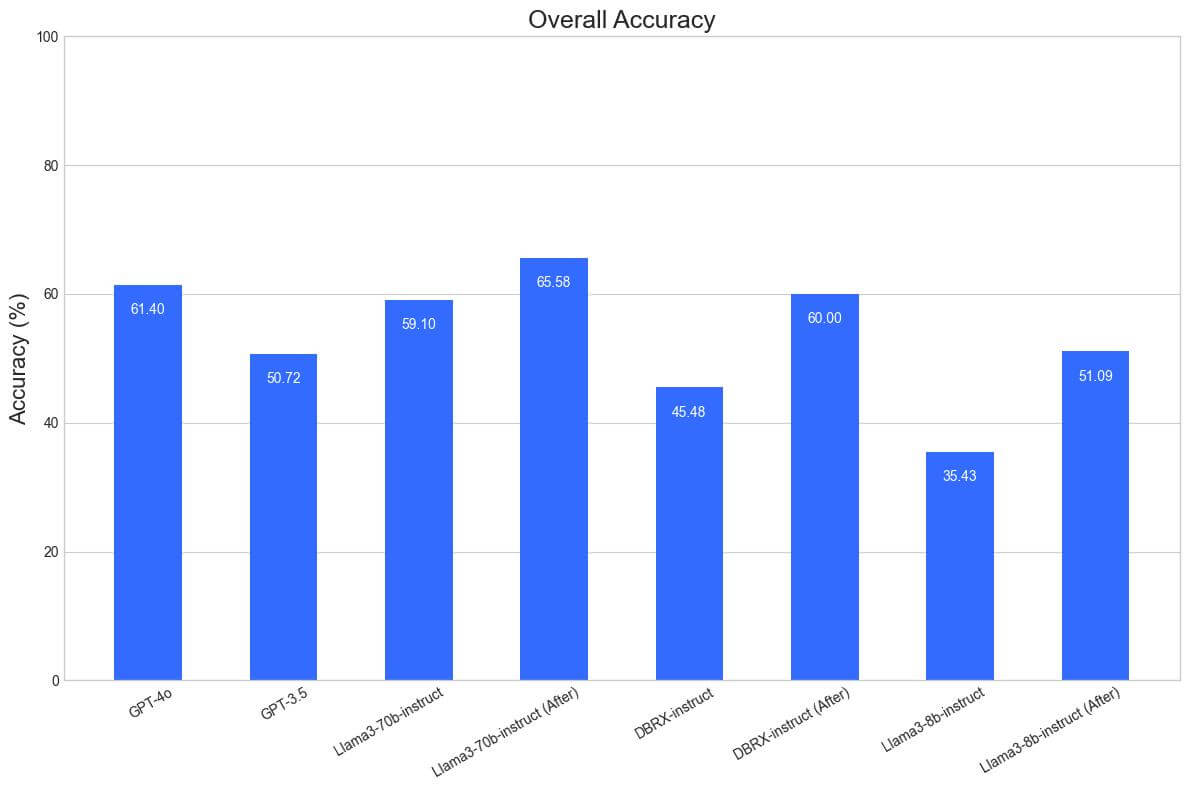
The mixture metric reveals that Llama3-70b-instruct, which was already approaching GPT-4o in high quality, surpasses it with our modifications. Each DBRX-instruct and Llama3-8b-instruct which begin at beneath GPT-3.5 high quality surpass it and start to method GPT-4o high quality on these benchmarks.
A further word is that LLMs don’t present ensures on whether or not they can generate output that adheres to a given schema. As demonstrated by the outcomes above, one of the best open supply fashions exhibit spectacular capabilities on this space. Nonetheless, they’re nonetheless inclined to hallucinations and occasional errors. One technique to mitigate these shortcomings is through the use of structured era (in any other case often called constrained decoding), a decoding method that gives ensures of the format during which an LLM outputs tokens. That is achieved by modifying the decoding step throughout LLM era to eradicate tokens that might violate given structural constraints. Common open supply structured era libraries are Outlines, Steering, and SGlang. From an engineering standpoint, structured era provides sturdy ensures which might be helpful for productionisation which is why we use it in our present implementation of operate calling on the Basis Fashions API. On this weblog, now we have solely introduced outcomes with unstructured era for simplicity. Nonetheless, we wish to emphasize {that a} well-implemented structured era pipeline ought to additional enhance the function-calling talents of an LLM.
5. Conclusion
Perform calling is a fancy functionality that considerably enhances the utility of LLMs in real-world functions. Nonetheless, evaluating and enhancing this functionality is way from easy. Listed here are some key takeaways:
- Complete analysis: No single benchmark tells the entire story. A holistic method, combining a number of analysis frameworks like BFCL and NFCL is essential to understanding a mannequin’s operate calling capabilities.
- Nuanced interpretation: Excessive scores on sure benchmarks, whereas crucial, are usually not at all times ample to ensure superior function-calling efficiency in apply. It’s important to grasp the strengths and limitations of every analysis metric.
- The ability of prompting: We’ve demonstrated that cautious prompting and output structuring can dramatically enhance a mannequin’s function-calling talents. This method allowed us to raise the efficiency of fashions like DBRX and Llama-3, bringing them nearer to and even surpassing GPT-4o in sure facets.
- Relevance detection: This often-overlooked side of operate calling is essential for real-world functions. Our enhancements on this space spotlight the significance of guiding fashions to cause about operate relevance.
To be taught extra about operate calling, overview our official documentation and check out our Foundational Mannequin APIs.