
{kind=link}
Introduction
If you’re requested to clarify RAG in English to somebody who doesn’t perceive a single phrase in that language—will probably be difficult for you, proper? Now, take into consideration machines(that don’t perceive human language) – once they attempt to make sense of human language, photos, and even music. That is the place vector embeddings come to the rescue! They supply a strong manner for complicated, high-dimensional information (like textual content or photos) to be translated into easy and dense numerical representations, making it a lot simpler for the algorithms to “perceive” and function such information.
On this put up, we are going to talk about the that means of vector embeddings, the several types of embeddings, and why they’re vital for generative AI going ahead. On high of this, we’ll present you the way to use embeddings for your self on the most typical platforms like Cohere and Hugging Face. Excited to unlock the world of embeddings and expertise the AI magic embedded inside? Let’s dig in!
Overview
- Vector embeddings rework complicated information into simplified numerical representations for AI fashions to course of it extra simply.
- Embeddings signify information factors as vectors, with proximity in vector house indicating semantic similarity.
- Various kinds of phrase, sentence, and picture embeddings serve particular AI duties resembling search and classification.
- Generative AI depends on embeddings to know context and generate related content material throughout textual content, photos, and extra.
- Instruments like Cohere and Hugging Face present quick access to pre-trained fashions for producing vector embeddings.
Understanding Vector Embeddings

Vector Embeddings are the mathematical representations of information factors in a steady vector house. Embeddings, merely put, are a solution to map information right into a fixed-dimensional vector house the place comparable information are positioned shut collectively on this new house.
For instance, in textual content, embeddings rework phrases, phrases, or complete sentences into dense vectors, the place the space between two vectors signifies their semantic similarity. This numerical illustration makes it simpler for machine studying fashions to work with numerous types of unstructured information, resembling textual content, photos, and even video.
Right here’s the pictorial illustration:

Right here’s the reason of every step:
Enter Knowledge:
- The left facet of the diagram reveals numerous sorts of information like Pictures, Paperwork, and Audio.
- These totally different information sorts are remodeled into embeddings (dense vector representations). The thought is to transform complicated information like photos or textual content into numerical vectors that encode their key options or semantic that means.
Rework into Embedding:
- Every enter information sort is processed utilizing pre-trained fashions (e.g., neural networks and transformers) which have been skilled on huge quantities of information. These fashions allow them to generate embeddings—dense numerical vectors the place every quantity captures some facet of the content material.
- For instance, sentences from paperwork or options of photos are represented as high-dimensional vectors.
Vector Illustration:
- After the transformation, the info is represented as a vector (proven as [ … ]). Every vector is a dense array of numbers.
- These embeddings may be thought-about factors in a high-dimensional house the place comparable information factors are positioned nearer whereas dissimilar ones are farther aside.
Nearest Neighbor Search:
- The important thing concept of vector search is to seek out the vectors closest to a question vector utilizing a nearest neighbor algorithm.
- When a brand new question is obtained (on the appropriate facet of the diagram), it is usually remodeled right into a vector (embedding). The system then compares this question vector with all of the saved embeddings to seek out the closest ones—i.e., the vectors most just like the question.
Outcomes:
- Based mostly on this nearest neighbor comparability, the system retrieves essentially the most comparable gadgets (photos, paperwork, or audio) and returns them as outcomes.
- These outcomes are sometimes ranked based mostly on similarity scores.
Why Are Embeddings Vital?
- Dimensionality Discount: Embeddings cut back high-dimensional, sparse information (like phrases in a big vocabulary) into low-dimensional, dense vectors. This course of preserves the semantic relationships whereas considerably lowering computational complexity.
- Semantic Similarity: The first objective of embeddings is to seize the context and that means of information. Phrases like “king” and “queen” will likely be nearer to one another within the vector house than unrelated phrases like “king” and “apple.”
- Mannequin Enter: Embeddings are fed into fashions for duties like classification, era, translation, and clustering. They convert uncooked enter right into a format that fashions can effectively course of.
Mathematical Illustration
Given a dataset D={x1,x2,…,xn}, embeddings rework every information level xi right into a vector vi such that:
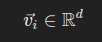
The place d is the dimension of the vector embedding, as an example, for phrase embeddings, a phrase www from the dataset is mapped to a vector vw that captures the semantics of the phrase within the context of your complete dataset.
Forms of Vector Embeddings
Varied sorts of embeddings exist relying on the form of information and the particular process at hand. Let’s discover a few of the commonest sorts.
1. Phrase Embeddings
Phrase embeddings are representations of particular person phrases. Standard fashions for producing phrase embeddings embrace:
- Word2Vec: Maps phrases to dense vectors based mostly on their co-occurrence in a neighborhood context.
- GloVe: International Vectors for Phrase Illustration, skilled on phrase co-occurrence counts over a corpus.
- FastText: An extension of Word2Vec that additionally accounts for subword data.
Use Case: Sentiment evaluation, part-of-speech tagging, and machine translation.
2. Sentence Embeddings
Sentence embeddings signify complete sentences, capturing their that means in a high-dimensional vector house. They’re significantly helpful when context past single phrases is vital.
- BERT (Bidirectional Encoder Representations from Transformers): A pre-trained transformer mannequin that generates contextualized sentence embeddings.
- Sentence-BERT: A modification of BERT that enables for quicker and extra environment friendly sentence comparability.
- InferSent: An older methodology for producing sentence embeddings specializing in pure language inference.
Use Case: Semantic textual similarity, paraphrase detection, and question-answering programs.
3. Doc Embeddings
Doc embeddings signify complete paperwork. They combination sentence or phrase embeddings over the doc’s size to supply a worldwide understanding of its contents.
- Doc2Vec: An extension of Word2Vec for representing complete paperwork as vectors.
- Transformer-based fashions (e.g., BERT, GPT): Usually used to derive document-level embeddings by processing your complete doc, using self-attention to generate extra contextualized embeddings.
Use Case: Doc classification, matter modeling, and summarization.
4. Picture and Multimodal Embeddings
Embeddings can signify different information sorts, resembling photos, audio, and video, along with textual content. They are often mixed with textual content embeddings for multimodal functions.
- Picture embeddings: Instruments like CLIP (Contrastive Language-Picture Pretraining) map photos and textual content right into a shared embedding house, enabling duties like picture captioning and visible search.
Use Case: Multimodal AI, visible search, and content material era.
Relevance of Vector Embeddings in Generative AI
Generative AI fashions like GPT closely depend on embeddings to know and generate content material. These embeddings enable generative fashions to understand context, patterns, and relationships inside information, that are important for producing significant output.
Embeddings Energy Key Points of Generative AI:
- Semantic Understanding: Embeddings enable generative fashions to know the semantics of language (or photos), that means we are able to write or generate coherent and related issues in context.
- Content material Era: Generative fashions use embeddings as enter to generate new information, be it textual content, photos, or music. For instance, GPT fashions use embeddings to generate human-like textual content based mostly on a given immediate.
- Multimodal Purposes: Embeddings enable fashions to mix a number of types of information (like textual content and pictures) to generate artistic outputs, resembling picture captions, text-to-image fashions, and cross-modal retrieval.
Methods to Use Cohere for Vector Embeddings?
Cohere is a platform that gives pre-trained language fashions optimized for duties like textual content era and embeddings. It supply API entry to highly effective embeddings for numerous downstream duties, together with search, classification, clustering, and suggestion programs.
Utilizing Cohere’s Embedding API
Cohere presents an easy-to-use API to generate embeddings for textual content. Right here’s a fast information to getting began:
Set up the Cohere SDK:
!pip set up cohereGenerate Textual content Embeddings: After getting your API key, you possibly can generate embeddings for textual content information as follows:
import cohere
co = cohere.Consumer(‘Your_Api_key’)
response = co.embed(
texts=[‘I HAVE ALWAYS BELIEVED THAT YOU SHOULD NEVER, EVER GIVE UP AND YOU SHOULD ALWAYS KEEP FIGHTING EVEN WHEN THERE’S ONLY A SLIGHTEST CHANCE.'],
mannequin="embed-english-v3.0",
input_type="classification"
)
print(response)OUTPUT

Output Rationalization:
- Embedded Vector: That is the core a part of the output. It’s a checklist of floating-point numbers (on this case, 1280 floats) that represents the contextual encoding for the enter textual content. Embeddings are mainly a dense vector illustration of the textual content. Which means that every quantity in our array is now capturing some key details about the that means, construction, or sentiment of your textual content.
Methods to Use Hugging Face for Vector Embeddings?
Hugging Face supplies an enormous repository of pre-trained fashions for NLP and different domains and instruments to fine-tune and generate embeddings.
Utilizing Hugging Face for Embeddings with Transformers
Hugging Face’s Transformers library is a well-liked framework for producing embeddings utilizing pre-trained fashions like BERT, RoBERTa, DistilBERT, and many others.
Set up the Transformers Library:
!pip set up transformers
!pip set up torch # for those who do not have already got PyTorch put inGenerate Sentence Embeddings: Use a pre-trained mannequin to create embeddings to your textual content.
from transformers import BertTokenizer, BertModel
import torch
# Load the tokenizer and mannequin from Hugging Face
model_name="bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
mannequin = BertModel.from_pretrained(model_name)
# Instance textual content
texts = ["I am from India", "I was born in India"]
# Tokenize the enter textual content
inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True)
# Move inputs by means of the mannequin
with torch.no_grad():
outputs = mannequin(**inputs)
# Get the hidden states (embeddings)
hidden_states = outputs.last_hidden_state
# For sentence embeddings, you would possibly need to use the pooled output,
# which is a [CLS] token embedding representing your complete sentence
sentence_embeddings = outputs.pooler_output
print(sentence_embeddings)
sentence_embeddings.formOUTPUT

Output Rationalization
The output tensor has the form [2, 768]. This means there are 2 sentences, every represented by a 768-dimensional vector. Every row corresponds to a distinct sentence:
- The primary row represents the sentence “I’m from India.”
- The second row represents the sentence, “I used to be born in India.”
Every quantity within the row is a price within the 768-dimensional embedding house. These values signify the options BERT extracted from the sentences, capturing elements like that means, context, and relationships between phrases.
2Refers back to the variety of sentences (two enter sentences).768Refers back to the dimension of the sentence embedding vector, which is commonplace for thebert-base-uncasedmannequin.
Vector Embeddings and Cosine Similarity

Vector Embeddings
Reiterating, in pure language processing, vector embeddings signify phrases, sentences, or different textual components as numerical vectors in a high-dimensional house. These vectors encode semantic details about the textual content, permitting fashions to seize relationships between phrases or sentences. Pre-trained fashions like BERT, RoBERTa, and GPT generate embeddings for textual content by projecting the enter textual content into this high-dimensional house.
Cosine Similarity
Cosine similarity measures how two vectors are comparable in path fairly than magnitude. It’s significantly helpful when evaluating high-dimensional vector embeddings in NLP, because the vectors’ precise size (magnitude) is usually much less vital than their orientation within the vector house.
Cosine similarity is a metric used to measure the angle between two vectors. It’s calculated as:
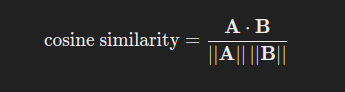
The place:
- A⋅B is the dot product of vectors A and B
- ∥A∥ and ∥B∥ are the magnitudes (lengths) of the vectors.
Relation between Vector Embeddings and Cosine Similarity
Right here’s the relation:
- Measuring Similarity: Some of the fashionable methods of calculating similarity is thru cosine similarity for vector embeddings in NLP. That’s, if in case you have two sentence embeddings from BERT — the cosine similarity offers you a rating between 0 to 1 that tells you the way contextually comparable the sentences are.
- Directional Similarity: Since embeddings typically reside in a really high-dimensional house, cosine similarity focuses on the angle between the vectors, ignoring their magnitude. That is vital as a result of embeddings typically encode relative semantic relationships, so two vectors pointing in an identical path signify comparable meanings, even when their magnitudes differ.
- Purposes:
- Sentence/Doc Similarity: Cosine similarity measures the semantic distance between two sentence embeddings. A worth close to 1 signifies a really excessive similarity between two sentences, whereas a price nearer to 0 or detrimental means there may be much less or no similarity between the sentences.
- Clustering: Embeddings with comparable cosine similarity may be clustered collectively in doc clustering or for matter modeling.
- Info Retrieval: When looking out by means of a corpus, cosine similarity can assist determine paperwork or sentences most just like a given question based mostly on their vector representations.
As an example:
Listed below are two sentences:
- “I like programming.”
- “I get pleasure from coding.”
These two sentences have totally different phrases however are semantically comparable. After passing these sentences by means of a mannequin like BERT, you acquire two totally different vector embeddings. By computing the cosine similarity between these vectors, you’d probably get a price near 1, indicating robust semantic similarity.
For those who evaluate a sentence like “I like programming” with one thing unrelated, like “It’s raining exterior”, the cosine similarity between their embeddings will probably be a lot decrease, nearer to 0, indicating little semantic overlap.
Right here is the cosine similarity of the textual content we used earlier:
from sklearn.metrics.pairwise import cosine_similarity
# Convert to numpy arrays for cosine similarity computation
embedding1 = sentence_embeddings[0].numpy().reshape(1, -1)
embedding2 = sentence_embeddings[1].numpy().reshape(1, -1)
# These are the sentences, “Hi there, how are you?", "I work in India!”
# Compute cosine similarity
similarity = cosine_similarity(embedding1, embedding2)
print(f"Cosine similarity between the 2 sentences: {similarity[0][0]}")OUTPUT

Output Rationalization:
0.9208 means that the 2 sentences have a really robust similarity of their semantic content material, that means they’re probably discussing comparable matters or expressing comparable concepts.
If this worth had been nearer to 1, it will point out near-identical that means, whereas a price nearer to 0 would point out no semantic similarity between the sentences. Values nearer to -1 (although unusual on this case) would point out opposing meanings.
In Abstract:
- Vector embeddings seize the semantics of phrases, sentences, or paperwork as high-dimensional vectors.
- Cosine similarity quantifies how comparable two vectors are by trying on the angle between them, making it a helpful metric for evaluating embeddings.
- The smaller the angle (nearer to 1), the extra semantically associated the embeddings are.
Conclusion
Vector embeddings are foundational in NLP and generative AI. They convert uncooked information into significant numerical representations that fashions can simply course of. Cohere and Hugging Face are two highly effective platforms that supply easy and efficient methods to generate embeddings for a variety of functions, from semantic search to clustering and suggestion programs.
Understanding the way to leverage these platforms successfully will unlock great potential for constructing smarter, extra context-aware AI programs, significantly within the ever-growing area of generative AI.
Additionally, in case you are searching for a Generative AI course on-line, then discover: the GenAI Pinnacle Program
Regularly Requested Questions
Ans. A vector embedding is a mathematical illustration that converts information, like textual content or photos, into dense numerical vectors in a high-dimensional house, preserving their that means and relationships.
Ans. Vector embeddings simplify complicated information, making it simpler for AI fashions to course of and perceive unstructured information, like language or photos, for duties like classification, search, and era.
Ans. In NLP, vector embeddings signify phrases, sentences, or paperwork as vectors, permitting fashions to seize semantic similarities and variations between textual components.
Ans. Cosine similarity measures the angle between two vectors, serving to decide how comparable two embeddings are based mostly on their path within the vector house, generally utilized in search and clustering.
Ans. Widespread sorts embrace phrase embeddings (e.g., Word2Vec, GloVe), sentence embeddings (e.g., BERT), and doc embeddings (e.g., Doc2Vec), every designed to seize totally different ranges of semantic data.
Hello, I’m Pankaj Singh Negi – Senior Content material Editor | Captivated with storytelling and crafting compelling narratives that rework concepts into impactful content material. I like studying about expertise revolutionizing our way of life.