
{kind=link}
Right now, AWS introduced that Amazon Kinesis Information Streams now helps report sizes as much as 10MiB – a tenfold enhance from the earlier restrict. With this launch, now you can publish intermittent bigger knowledge payloads in your knowledge streams whereas persevering with to make use of present Kinesis Information Streams APIs in your functions with out further effort. This launch is accompanied by a 2x enhance within the most PutRecords request measurement from 5MiB to 10MiB, simplifying knowledge pipelines and lowering operational overhead for IoT analytics, change knowledge seize, and generative AI workloads.
On this publish, we discover Amazon Kinesis Information Streams massive report assist, together with key use circumstances, configuration of most report sizes, throttling concerns, and greatest practices for optimum efficiency.
Actual world use circumstances
As knowledge volumes develop and use circumstances evolve, we’ve seen rising demand for supporting bigger report sizes in streaming workloads. Beforehand, once you wanted to course of data bigger than 1MiB, you had two choices:
- Break up massive data into a number of smaller data in producer functions and reassemble them in client functions
- Retailer massive data in Amazon Easy Storage Service (Amazon S3) and ship solely metadata via Kinesis Information Streams
Each these approaches are helpful, however they add complexity to knowledge pipelines, requiring further code, rising operational overhead, and complicating error dealing with and debugging, notably when clients must stream massive data intermittently.
This enhancement improves the benefit of use and reduces operational overhead for purchasers dealing with intermittent knowledge payloads throughout varied industries and use circumstances. Within the IoT analytics area, related automobiles and industrial gear are producing rising volumes of sensor telemetry knowledge, with the scale of particular person telemetry data often exceeding the earlier 1MiB restrict in Kinesis. This required clients to implement complicated workarounds, reminiscent of splitting massive data into a number of smaller ones or storing the big data individually and solely sending metadata via Kinesis. Equally, in database change knowledge seize (CDC) pipelines, massive transaction data might be produced, particularly throughout bulk operations or schema modifications. Within the machine studying and generative AI area, workflows are more and more requiring the ingestion of bigger payloads to assist richer function units and multi-modal knowledge varieties like audio and pictures. The elevated Kinesis report measurement restrict from 1MiB to 10MiB limits the necessity for these kind of complicated workarounds, simplifying knowledge pipelines and lowering operational overhead for purchasers in IoT, CDC, and superior analytics use circumstances. Clients can now extra simply ingest and course of these intermittent massive knowledge data utilizing the identical acquainted Kinesis APIs.
The way it works
To begin processing bigger data:
- Replace your stream’s most report measurement restrict (
maxRecordSize) via the AWS Console, AWS CLI, or AWS SDKs. - Proceed utilizing the identical
PutRecordandPutRecordsAPIs for producers. - Proceed utilizing the identical
GetRecordsorSubscribeToShardAPIs for shoppers.
Your stream will probably be in Updating standing for just a few seconds earlier than being able to ingest bigger data.
Getting began
To begin processing bigger data with Kinesis Information Streams, you possibly can replace the utmost report measurement through the use of the AWS Administration Console, CLI or SDK.
On the AWS Administration Console,
- Navigate to the Kinesis Information Streams console.
- Select your stream and choose the Configuration tab.
- Select Edit (subsequent to Most report measurement).
- Set your required most report measurement (as much as 10MiB).
- Save your modifications.
Be aware: This setting solely adjusts the utmost report measurement for this Kinesis knowledge stream. Earlier than rising this restrict, confirm that every one downstream functions can deal with bigger data.
Commonest shoppers reminiscent of Kinesis Shopper Library (beginning with model 2.x), Amazon Information Firehose supply to Amazon S3 and AWS Lambda assist processing data bigger than 1 MiB. To be taught extra, check with the Amazon Kinesis Information Streams documentation for big data.
You can even replace this setting utilizing the AWS CLI:
Or utilizing the AWS SDK:
Throttling and greatest practices for optimum efficiency
Particular person shard throughput limits of 1MiB/s for writes and 2MiB/s for reads stay unchanged with assist for bigger report sizes. To work with massive data, let’s perceive how throttling works. In a stream, every shard has a throughput capability of 1 MiB per second. To accommodate massive data, every shard briefly bursts as much as 10MiB/s, ultimately averaging out to 1MiB per second. To assist visualize this conduct, consider every shard having a capability tank that refills at 1MiB per second. After sending a big report (for instance, a 10MiB report), the tank begins refilling instantly, permitting you to ship smaller data as capability turns into accessible. This capability to assist massive data is repeatedly refilled into the stream. The speed of refilling will depend on the scale of the big data, the scale of the baseline report, the general visitors sample, and your chosen partition key technique. While you course of massive data, every shard continues to course of baseline visitors whereas leveraging its burst capability to deal with these bigger payloads.
For instance how Kinesis Information Streams handles totally different proportions of huge data, let’s look at the outcomes a easy check. For our check configuration, we arrange a producer that sends knowledge to an on-demand stream (defaults to 4 shards) at a charge of fifty data per second. The baseline data are 10KiB in measurement, whereas massive data are 2MiB every. We carried out a number of check circumstances by progressively rising the proportion of huge data from 1% to five% of the whole stream visitors, together with a baseline case containing no massive data. To make sure constant testing circumstances, we distributed the big data uniformly over time for instance, within the 1% state of affairs, we despatched one massive report for each 100 baseline data. The next graph exhibits the outcomes:
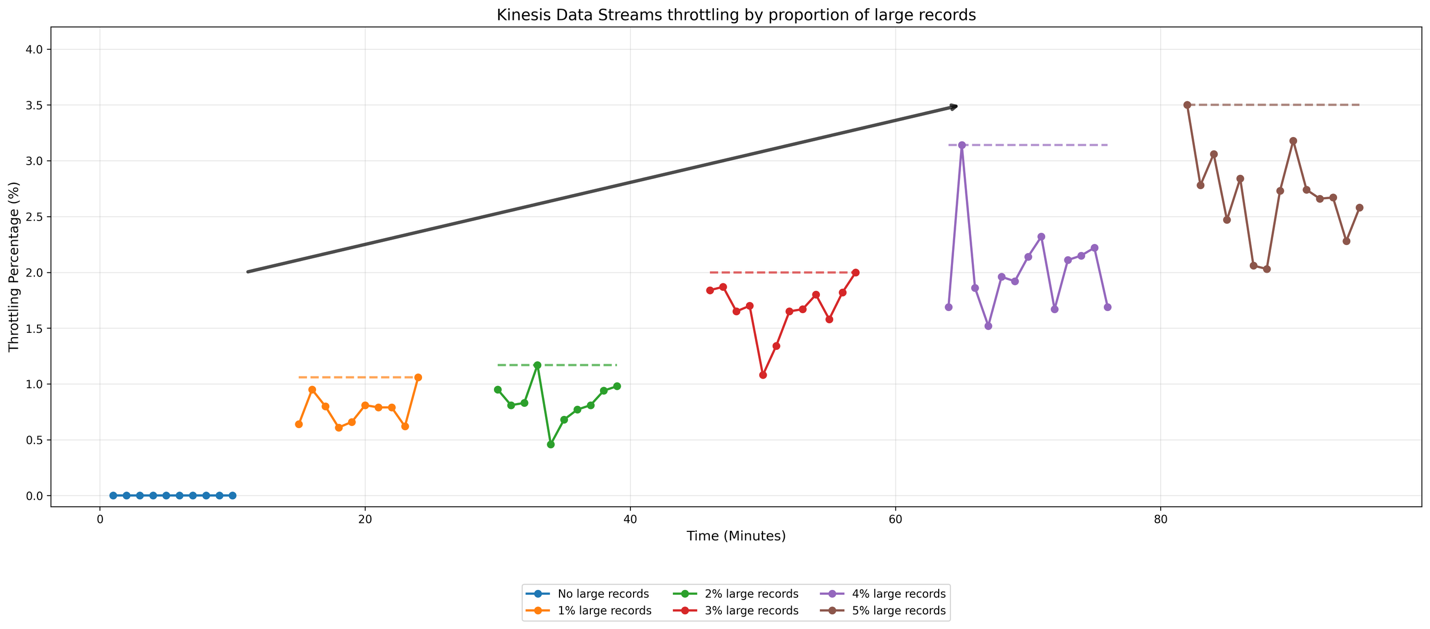
Within the graph, horizontal annotations point out throttling incidence peaks. The baseline state of affairs, represented by the blue line, exhibits minimal throttling occasions. Because the proportion of huge data will increase from 1% to five%, we observe a rise within the charge at which your stream throttles your knowledge, with a notable acceleration in throttling occasions between the two% and 5% eventualities. This check demonstrates how Kinesis Information Streams manages rising proportion of huge data.
We suggest sustaining massive data at 1-2% of your complete report depend for optimum efficiency. In manufacturing environments, precise stream conduct varies based mostly on three key elements: the scale of baseline data, the scale of huge data, and the frequency at which massive data seem within the stream. We suggest that you just check together with your demand sample to find out the precise conduct.
With on-demand streams, when the incoming visitors exceeds 500 KB/s per shard, it splits the shard inside quarter-hour. The guardian shard’s hash key values are redistributed evenly throughout baby shards. Kinesis robotically scales the stream to extend the variety of shards, enabling distribution of huge data throughout a bigger variety of shards relying on the partition key technique employed.
For optimum efficiency with massive data:
- Use a random partition key technique to distribute massive data evenly throughout shards.
- Implement backoff and retry logic in producer functions.
- Monitor shard-level metrics to determine potential bottlenecks.
When you nonetheless must repeatedly stream of huge data, think about using Amazon S3 to retailer payloads and ship solely metadata references to the stream. Consult with Processing massive data with Amazon Kinesis Information Streams for extra info.
Conclusion
Amazon Kinesis Information Streams now helps report sizes as much as 10MiB, a tenfold enhance from the earlier 1MiB restrict. This enhancement simplifies knowledge pipelines for IoT analytics, change knowledge seize, and AI/ML workloads by eliminating the necessity for complicated workarounds. You possibly can proceed utilizing present Kinesis Information Streams APIs with out further code modifications and profit from elevated flexibility in dealing with intermittent massive payloads.
- For optimum efficiency, we suggest sustaining massive data at 1-2% of complete report depend.
- For greatest outcomes with massive data, implement a uniformly distributed partition key technique to evenly distribute data throughout shards, embody backoff and retry logic in producer functions, and monitor shard-level metrics to determine potential bottlenecks.
- Earlier than rising the utmost report measurement, confirm that every one downstream functions and shoppers can deal with bigger data.
We’re excited to see the way you’ll leverage this functionality to construct extra highly effective and environment friendly streaming functions. To be taught extra, go to the Amazon Kinesis Information Streams documentation.
In regards to the authors