

Researchers at NVIDIA are working to allow scalable artificial era for robotic mannequin coaching. Supply: NVIDIA
A significant problem in robotics is coaching robots to carry out new duties with out the large effort of amassing and labeling datasets for each new process and surroundings. Current analysis efforts from NVIDIA intention to unravel this problem via the usage of generative AI, world basis fashions like NVIDIA Cosmos, and knowledge era blueprints equivalent to NVIDIA Isaac GR00T-Mimic and GR00T-Goals.
NVIDIA lately lined how analysis is enabling scalable artificial knowledge era and robotic mannequin coaching workflows utilizing world basis fashions, equivalent to:
- DreamGen: The analysis basis of the NVIDIA Isaac GR00T-Goals blueprint.
- GR00T N1: An open basis mannequin that allows robots to study generalist expertise throughout numerous duties and embodiments from actual, human, and artificial knowledge.
- Latent motion pretraining from movies: An unsupervised methodology that learns robot-relevant actions from large-scale movies with out requiring handbook motion labels.
- Sim-and-real co-training: A coaching strategy that mixes simulated and real-world robotic knowledge to construct extra strong and adaptable robotic insurance policies.
World basis fashions for robotics
Cosmos world basis fashions (WFMs) are skilled on thousands and thousands of hours of real-world knowledge to foretell future world states and generate video sequences from a single enter picture, enabling robots and autonomous automobiles to anticipate upcoming occasions. This predictive functionality is essential for artificial knowledge era pipelines, facilitating the fast creation of numerous, high-fidelity coaching knowledge.
This WFM strategy can considerably speed up robotic studying, improve mannequin robustness, and cut back growth time from months of handbook effort to only hours, in accordance with NVIDIA.
DreamGen
DreamGen is an artificial knowledge era pipeline that addresses the excessive value and labor of amassing large-scale human teleoperation knowledge for robotic studying. It’s the foundation for NVIDIA Isaac GR00T-Goals, a blueprint for producing huge artificial robotic trajectory knowledge utilizing world basis fashions.
Conventional robotic basis fashions require intensive handbook demonstrations for each new process and surroundings, which isn’t scalable. Simulation-based alternate options typically endure from the sim-to-real hole and require heavy handbook engineering.
DreamGen overcomes these challenges through the use of WFMs to create sensible, numerous coaching knowledge with minimal human enter. This strategy allows scalable robotic studying and powerful generalization throughout behaviors, environments, and robotic embodiments.
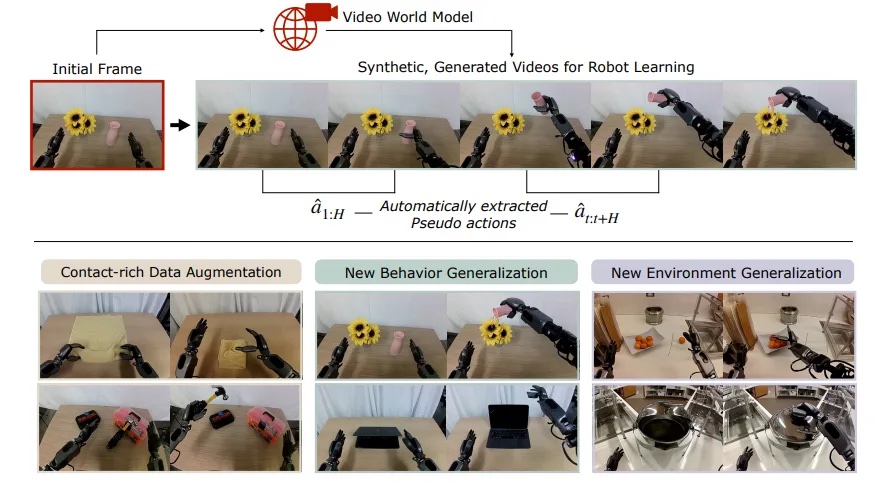
Generalization via the DreamGen artificial knowledge pipeline. | Supply: NVIDIA
The DreamGen pipeline consists of 4 key steps:
- Publish-train world basis mannequin: Adapt a world basis mannequin like Cosmos-Predict2 to the goal robotic utilizing a small set of actual demonstrations. Cosmos-Predict2 can generate high-quality pictures from textual content (text-to-image) and visible simulations from pictures or movies (video-to-world).
- Generate artificial movies: Use the post-trained mannequin to create numerous, photorealistic robotic movies for brand spanking new duties and environments from picture and language prompts.
- Extract pseudo-actions: Apply a latent motion mannequin or inverse dynamics mannequin (IDM) to show these movies into labeled motion sequences (neural trajectories).
- Practice robotic insurance policies: Use the ensuing artificial trajectories to coach visuomotor insurance policies, enabling robots to carry out new behaviors and generalize to unseen eventualities.
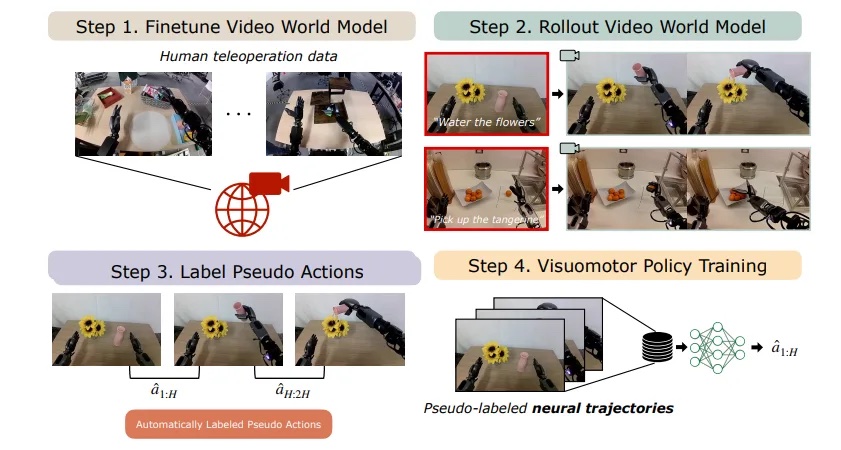
Overview of the DreamGen pipeline. | Supply: NVIDIA
DreamGen Bench
DreamGen Bench is a specialised benchmark designed to judge how successfully video generative fashions adapt to particular robotic embodiments whereas internalizing rigid-body physics and generalizing to new objects, behaviors, and environments. It assessments 4 main world basis fashions—NVIDIA Cosmos, WAN 2.1, Hunyuan, and CogVideoX—measuring two crucial metrics:
- Instruction following: DreamGen Bench assesses whether or not generated movies precisely replicate process directions — equivalent to “choose up the onion” — evaluated utilizing vision-language fashions (VLMs) like Qwen-VL-2.5 and human annotators.
- Physics following: It quantifies bodily realism utilizing instruments equivalent to VideoCon-Physics and Qwen-VL-2.5 to make sure that movies obey real-world physics.
As seen within the graph beneath, fashions scoring increased on DreamGen Bench—which means they generate extra sensible and instruction-following artificial knowledge—persistently result in higher efficiency when robots are skilled and examined on actual manipulation duties. This constructive relationship exhibits that investing in stronger WFMs not solely improves the standard of artificial coaching knowledge but in addition interprets straight into extra succesful and adaptable robots in apply.
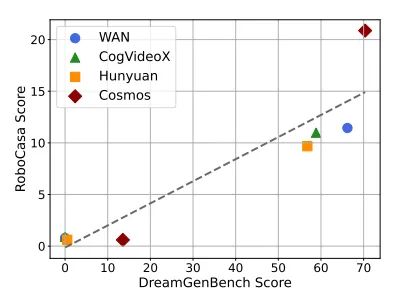
Optimistic efficiency correlation between DreamGen Bench and RoboCasa. | Supply: NVIDIA
NVIDIA Isaac GR00T-Goals
Isaac GR00T-Goals, based mostly on DreamGen analysis, is a workflow for producing massive datasets of artificial trajectory knowledge for robotic actions. These datasets are used to coach bodily robots whereas saving vital time and handbook effort in contrast with amassing real-world motion knowledge, asserted NVIDIA.
GR00T-Goals makes use of the Cosmos Predict2 WFM and Cosmos Purpose to generate knowledge for various duties and environments. Cosmos Purpose fashions embody a multimodal LLM (massive language mannequin) that generates bodily grounded responses to person prompts.

Basis fashions and workflows for coaching robots
Imaginative and prescient-language-action (VLA) fashions might be post-trained utilizing knowledge generated from WFMs to allow novel behaviors and operations in unseen environments, defined NVIDIA.
NVIDIA Analysis used the GR00T-Goals blueprint to generate artificial coaching knowledge to develop GR00T N1.5, an replace of GR00T N1 in simply 36 hours. This course of would have taken practically three months utilizing handbook human knowledge assortment.
GR00T N1, an open basis mannequin for generalist humanoid robots, marks a serious breakthrough on this planet of robotics and AI, the corporate stated. Constructed on a dual-system structure impressed by human cognition, GR00T N1 unifies imaginative and prescient, language, and motion, enabling robots to grasp directions, understand their environments, and execute complicated, multi-step duties.
GR00T N1 builds on strategies like LAPA (latent motion pretraining for basic motion fashions) to study from unlabeled human movies and approaches like sim-and-real co-training, which blends artificial and real-world knowledge for stronger generalization. We’ll study LAPA and sim-and-real co-training later.
By combining these improvements, GR00T N1 doesn’t simply comply with directions and execute duties—it units a brand new benchmark for what generalist humanoid robots can obtain in complicated, ever-changing environments, NVIDIA stated.
GR00T N1.5 is an upgraded open basis mannequin for generalist humanoid robots, constructing on the unique GR00T N1, which includes a refined VLM skilled on a various mixture of actual, simulated, and DreamGen-generated artificial knowledge.
With enhancements in structure and knowledge high quality, GR00T N1.5 delivers increased success charges, higher language understanding, and stronger generalization to new objects and duties, making it a extra strong and adaptable resolution for superior robotic manipulation.
Latent Motion Pretraining from Movies
LAPA is an unsupervised methodology for pre-training VLA fashions that removes the necessity for costly, manually labeled robotic motion knowledge. Moderately than counting on massive, annotated datasets—that are each pricey and time-consuming to collect—LAPA makes use of over 181,000 unlabeled Web movies to study efficient representations.
This methodology delivers a 6.22% efficiency increase over superior fashions on real-world duties and achieves greater than 30x better pretraining effectivity, making scalable and strong robotic studying way more accessible and environment friendly, stated NVIDIA.
The LAPA pipeline operates via a three-stage course of:
- Latent motion quantization: A Vector Quantized Variational AutoEncoder (VQ-VAE) mannequin learns discrete “latent actions” by analyzing transitions between video frames, making a vocabulary of atomic behaviors equivalent to greedy or pouring. Latent actions are low-dimensional, realized representations that summarize complicated robotic behaviors or motions, making it simpler to regulate or imitate high-dimensional actions.
- Latent pretraining: A VLM is pre-trained utilizing conduct cloning to foretell these latent actions from the primary stage based mostly on video observations and language directions. Conduct cloning is a technique the place a mannequin learns to repeat or imitate actions by mapping observations to actions, utilizing examples from demonstration knowledge.
- Robotic post-training: The pretrained mannequin is then post-trained to adapt to actual robots utilizing a small labeled dataset, mapping latent actions to bodily instructions.
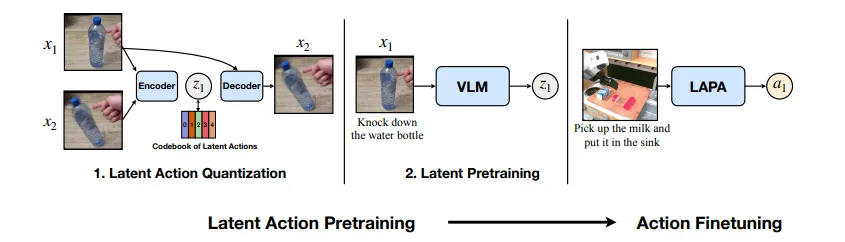
Overview of latent motion pretraining. | Supply: NVIDIA
Sim-and-real co-training workflow
Robotic coverage coaching faces two crucial challenges: the excessive value of amassing real-world knowledge and the “actuality hole,” the place insurance policies skilled solely in simulation typically fail to carry out properly in actual bodily environments.
The sim-and-real co-training workflow addresses these points by combining a small set of real-world robotic demonstrations with massive quantities of simulation knowledge. This strategy allows the coaching of sturdy insurance policies whereas successfully decreasing prices and bridging the fact hole.
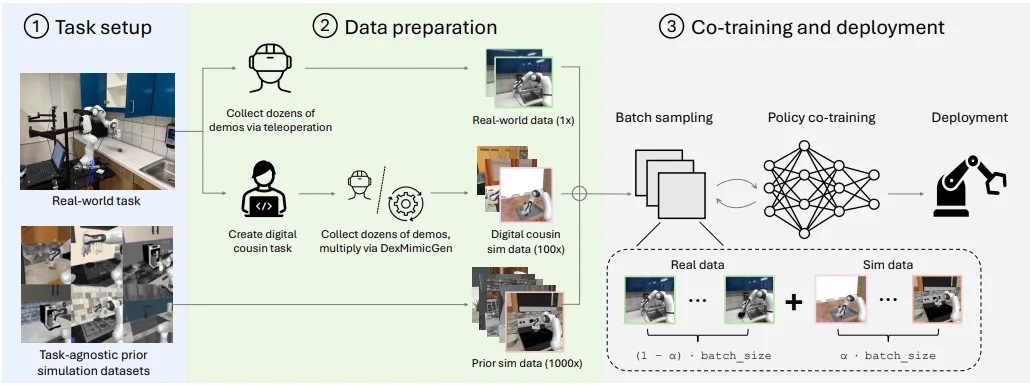
Overview of the totally different levels of acquiring knowledge. | Supply: NVIDIA
The important thing steps within the workflow are:
- Job and scene setup: Setup of a real-world process and the choice of task-agnostic prior simulation datasets.
- Knowledge preparation: On this knowledge preparation stage, real-world demonstrations are collected from bodily robots, whereas further simulated demonstrations are generated, each as task-aware “digital cousins,” which carefully match the actual duties, and as numerous, task-agnostic prior simulations.
- Co-training parameter tuning: These totally different knowledge sources are then blended at an optimized co-training ratio, with an emphasis on aligning digicam viewpoints and maximizing simulation variety fairly than photorealism. The ultimate stage includes batch sampling and coverage co-training utilizing each actual and simulated knowledge, leading to a strong coverage that’s deployed on the robotic.

Visible of simulation and real-world duties. | Supply: NVIDIA
As proven within the picture beneath, rising the variety of real-world demonstrations can enhance the success price for each real-only and co-trained insurance policies. Even with 400 actual demonstrations, the co-trained coverage persistently outperformed the real-only coverage by a median of 38%, demonstrating that sim-and-real co-training stays useful even in data-rich settings.
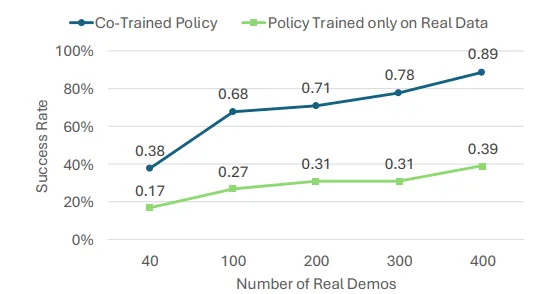
Graph displaying the efficiency of the co-trained coverage and coverage skilled on actual knowledge solely. | Supply: NVIDIA
Robotics ecosystem begins adopting new fashions
Main organizations are adopting these workflows from NVIDIA analysis to speed up growth. Early adopters of GR00T N fashions embody:
- AeiRobot: Utilizing the fashions to allow its industrial robots to grasp pure language for complicated pick-and-place duties.
- Foxlink: Leveraging the fashions to enhance the pliability and effectivity of its industrial robotic arms.
- Lightwheel: Validating artificial knowledge for the quicker deployment of humanoid robots in factories utilizing the fashions.
- NEURA Robotics: Evaluating the fashions to speed up the event of its family automation programs.
 In regards to the writer
In regards to the writer

{kind=link}
Oluwaseun Doherty is a technical advertising and marketing engineer intern at NVIDIA, the place he works on robotic studying purposes on the NVIDIA Isaac Sim, Isaac Lab, and Isaac GR00T platforms. Doherty is at present pursuing a bachelor’s diploma in pc science at Southeastern Louisiana College, the place he focuses on knowledge science, AI, and robotics.
Editor’s observe: This text was syndicated from NVIDIA’s technical weblog.