
{kind=link}
Amazon OpenSearch Service is a managed service that makes it easy to deploy, safe, and function OpenSearch clusters at scale within the AWS Cloud. A typical OpenSearch cluster is comprised of cluster supervisor, knowledge, and coordinator nodes. It is suggested to have three cluster supervisor nodes, and one in every of them might be elected as a pacesetter node.
Amazon OpenSearch Service launched assist for 1,000-node OpenSearch Service clusters able to dealing with 500,000 shards with OpenSearch Service model 2.17. For big clusters, we have now recognized bottlenecks in admin API interactions (with the chief) and launched enhancements in OpenSearch Service model 2.17. These enhancements have helped OpenSearch Service to publish cluster metrics and monitor at identical frequency for giant clusters whereas sustaining the optimum useful resource utilization (lower than 10% CPU and fewer than 75% JVM utilization) on the chief node (16 core CPU with 64 GB JVM heap). It has additionally ensured that metadata administration will be carried out on giant clusters with predictable latency with out destabilizing the chief node.
Normal monitoring of an OpenSearch node utilizing well being verify and statistics API endpoints doesn’t trigger seen load to the chief. However because the variety of nodes enhance within the cluster, the quantity of those monitoring calls additionally will increase proportionally. The rise within the name quantity coupled with the much less optimum implementation of those endpoints overwhelms the chief node, leading to stability points. On this put up, we reveal the completely different bottlenecks that had been recognized and the corresponding options that had been applied in OpenSearch Service to scale cluster supervisor for giant cluster deployments. These optimizations can be found to all new domains or present domains upgraded to OpenSearch Service variations 2.17 or above.
Cluster state
To grasp the varied bottlenecks with the cluster supervisor, let’s study the cluster state, whose administration is the core operation of the chief. The cluster state comprises the next key metadata data:
- Cluster settings
- Index metadata, which incorporates index settings, mappings, and alias
- Routing desk and shard metadata, which comprises particulars of shard allocation to nodes
- Node data and attributes
- Snapshot data, customized metadata, and so forth
Node, index, and shard are managed as first-class entities by the cluster supervisor and comprise data resembling identifier, identify, and attributes for every of their cases.
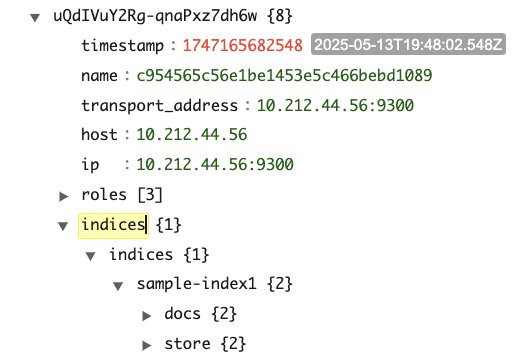
The next screenshots are from a pattern cluster state for a cluster with three cluster supervisor and three knowledge nodes. The cluster has a single index (sample-index1) with one main and two replicas.

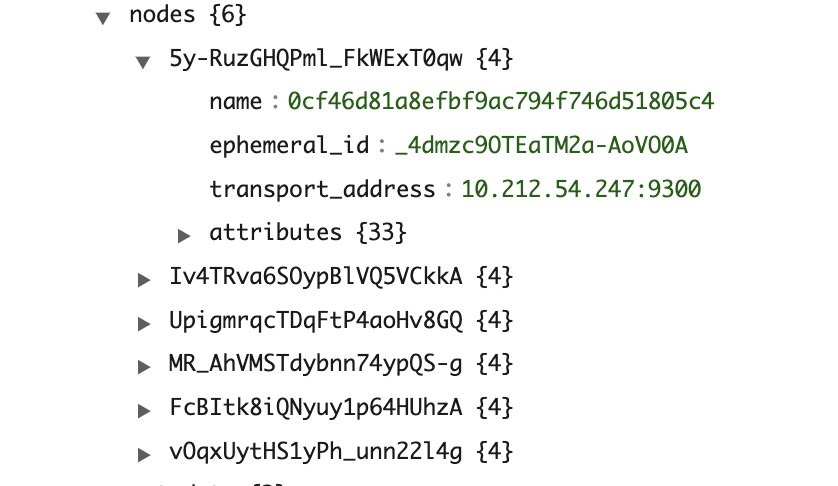
As proven within the screenshots, the variety of entries within the cluster state is as follows:
IndexMetadata(metadata#indices) has entries equal to the whole variety of indexesRoutingTable(routing_table) has entries equal to the variety of indexes multiplied by the variety of shards per indexNodeInfo(nodes) has entries equal to the variety of nodes within the cluster
The scale of a pattern cluster state with six nodes, one index, and three shards is round 15 KB (dimension of JSON response from the API). Think about a cluster with 1,000 nodes, which has 10,000 indexes with a mean of fifty shards per index. The cluster state would have 10,000 entries for IndexMetadata, 500,000 entries for RoutingTable, and 1,000 entries for NodeInfo.
Bottleneck 1: Cluster state communication
OpenSearch offers admin APIs as a REST endpoint for customers to handle and configure the cluster metadata. Admin API requests are dealt with by both coordinator node (or) by knowledge node if the cluster doesn’t have devoted coordinator node provisioned. You need to use admin APIs to verify cluster well being, modify settings, retrieve statistics, and extra. A few of the examples are the CAT, Cluster Settings, and Node Stats APIs.
The next diagram illustrates the admin API management circulate.
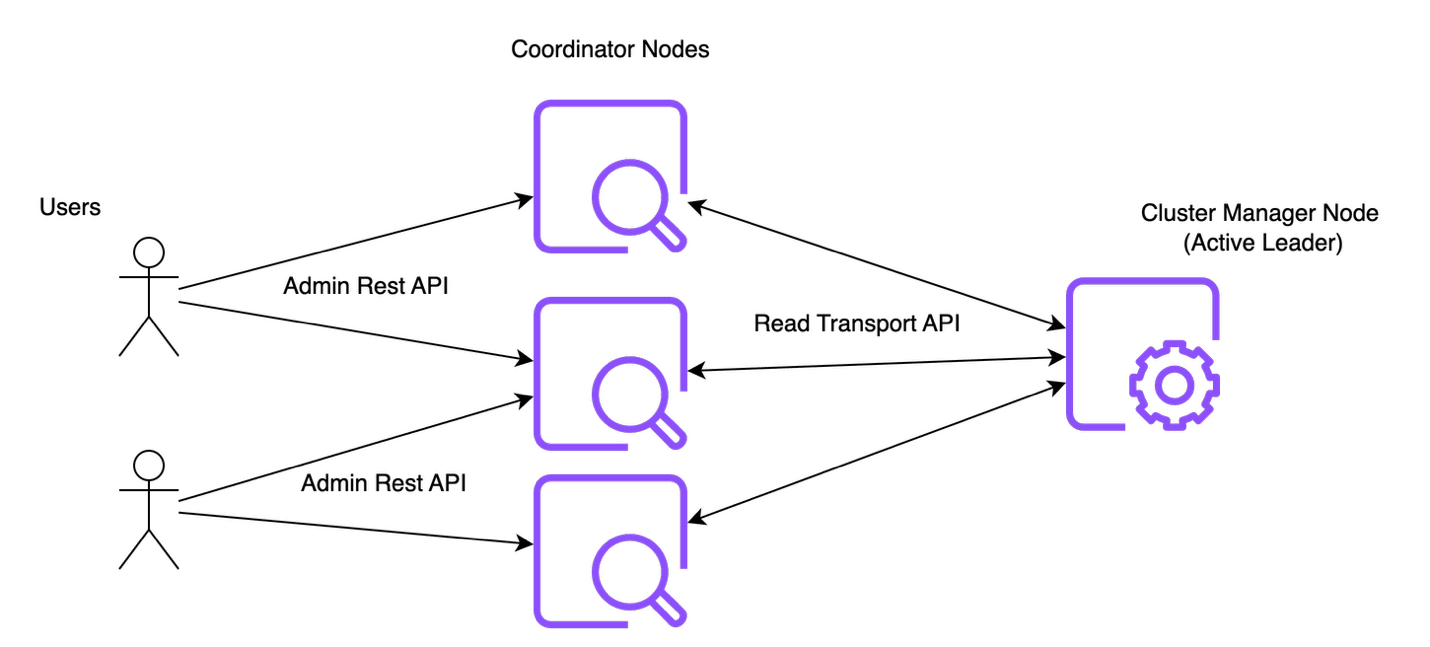
Let’s take into account a Learn API request to fetch details about the cluster settings.
- The person makes the decision to the HTTP endpoint backed by the coordinator node.
- The coordinator node initiates an inside transport name to the chief of the cluster.
- The transport handler within the chief node performs a filter and collection of metadata primarily based on the enter request from the newest cluster state.
- The processed cluster state is then returned again to the coordinating node, which then generates the response and finishes the request processing.
The cluster state processing on the nodes is proven within the following diagram.
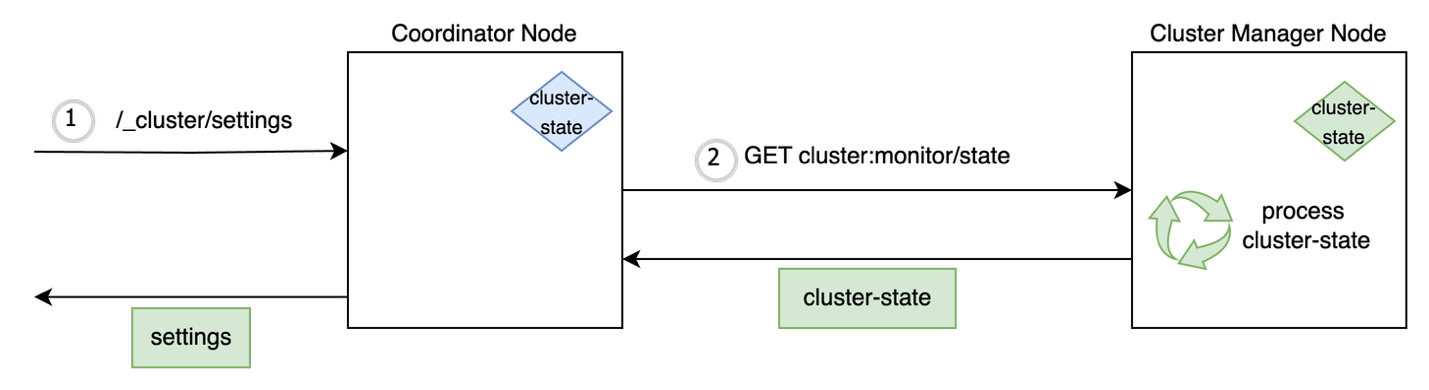
As mentioned earlier, a lot of the admin learn requests require the newest cluster state and the node which processes the API request and makes a _cluster/state name to the chief. In a cluster setup of 1,000 nodes and 500,000 shards, the scale of the cluster state can be round 250 MB. This could overload chief and trigger the next points:
- CPU utilization will increase on the chief on account of simultaneous admin calls as a result of the chief has to vend the newest state to many coordinating nodes within the cluster concurrently.
- The heap reminiscence consumption of the cluster state can develop to multiples of 100 MB relying upon the variety of index mappings and settings configured by the person. It causes JVM reminiscence strain to construct on the chief, inflicting frequent rubbish assortment pauses.
- Repeated serialization and switch of the massive cluster state causes transport employee threads to be busy on the chief node, doubtlessly inflicting delays and timeouts of additional requests.
The chief node sends periodic ping requests to follower nodes and requires transport threads to course of the responses. As a result of the variety of threads serving the transport channel is proscribed (defaults to the variety of processor cores), the responses usually are not processed in a well timed vogue. The leader-follower well being checks within the cluster get timed out, thereby inflicting a spiral impact of nodes leaving the cluster and extra shard recoveries being initiated by the chief.
Resolution: Newest native cluster state
Cluster state is versioned utilizing two lengthy fields: time period and model. The time period quantity is incremented each time a brand new chief is elected, and the model quantity is incremented with each metadata replace. Provided that the newest cluster state is cached on all of the nodes, it may be used to serve the admin API request whether it is up-to-date with the chief. To verify the freshness of the cached copy, a lightweight transport API is launched, which fetches solely the time period and model comparable to the newest cluster state from chief. The request-coordinating node matches it with the native time period and model, and in the event that they’re the identical, it makes use of the native cluster sate to serve the admin API learn request. If the cached cluster state is out of sync, the node makes a subsequent transport name to fetch the newest cluster state after which serves the incoming API request. This offloads the accountability of serving learn requests to the coordinating node, thereby decreasing the load on the chief node.
Cluster state processing on the nodes after the optimization is proven within the following diagram.
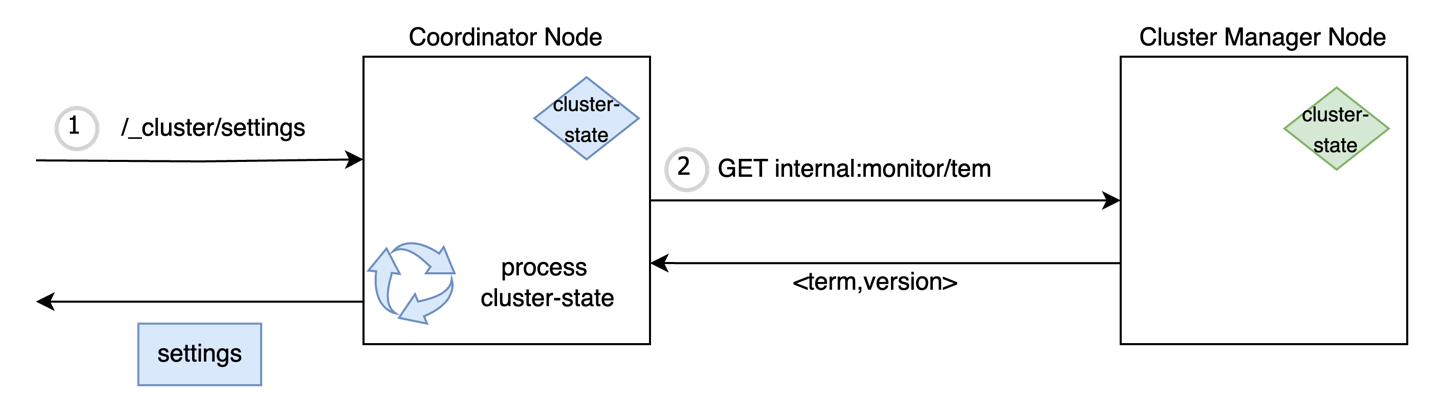
Time period-version checks for cluster state processing at the moment are utilized by 17 learn APIs throughout the _cat and _cluster APIs in OpenSearch.
Impression: Much less CPU useful resource utilization on chief
From our load checks, we noticed at the very least 50% discount in CPU utilization and not using a change within the API latency because of the aforementioned enchancment. The load check was carried out on an OpenSearch cluster consisting of three cluster supervisor nodes (8 cores every), 5 knowledge nodes (64 cores every), and 25,000 shards with a cluster state dimension of round 50 MB. The workload consists of the next admin APIs invoked, with periodicity talked about within the following desk:
/_cluster/state/_cat/indices/_cat/shards/_cat/allocation
| Request Rely / 5 minutes | CPU (max) | |
| Current Setup | With Optimization | |
| 3000 | 14% | 7% |
| 6000 | 20% | 10% |
| 9000 | 28% | 12% |
Bottleneck 2: Scatter-gather nature of statistics admin APIs
The subsequent group of admin APIs are used to fetch the statistics data of the cluster. These APIs embody _cat/indices, _cat/shards, _cat/segments, _cat/nodes, _cluster/stats, and _nodes/stats, to call just a few. In contrast to metadata, which is managed by the chief, the statistics data is distributed throughout the information nodes within the cluster.
For instance, take into account the response to the _cat/indices API for the index sample-index1:
The values for fields docs.depend, docs.deleted , retailer.dimension, and pri.retailer.dimension are fetched from the information nodes, which have the corresponding shards, and are then aggregated by the coordinating node. To compute the previous response for sample-index1, the coordinator node collects the statistics responses from three knowledge nodes internet hosting one main and two reproduction shards, respectively.
Each knowledge node within the cluster collects statistics associated to operations resembling indexing, search, merges, and flushes for the shards it manages. Each shard within the cluster has about 150 indices metrics tracked throughout 20 metric teams.
The response from the information node to coordinator comprises all of the shard statistics of the index and never simply those (docs and retailer stats) requested by the person. The response dimension of stats returned from knowledge node for a single shard is round 4 KB. The next diagram illustrates the stats knowledge circulate amongst nodes in a cluster.
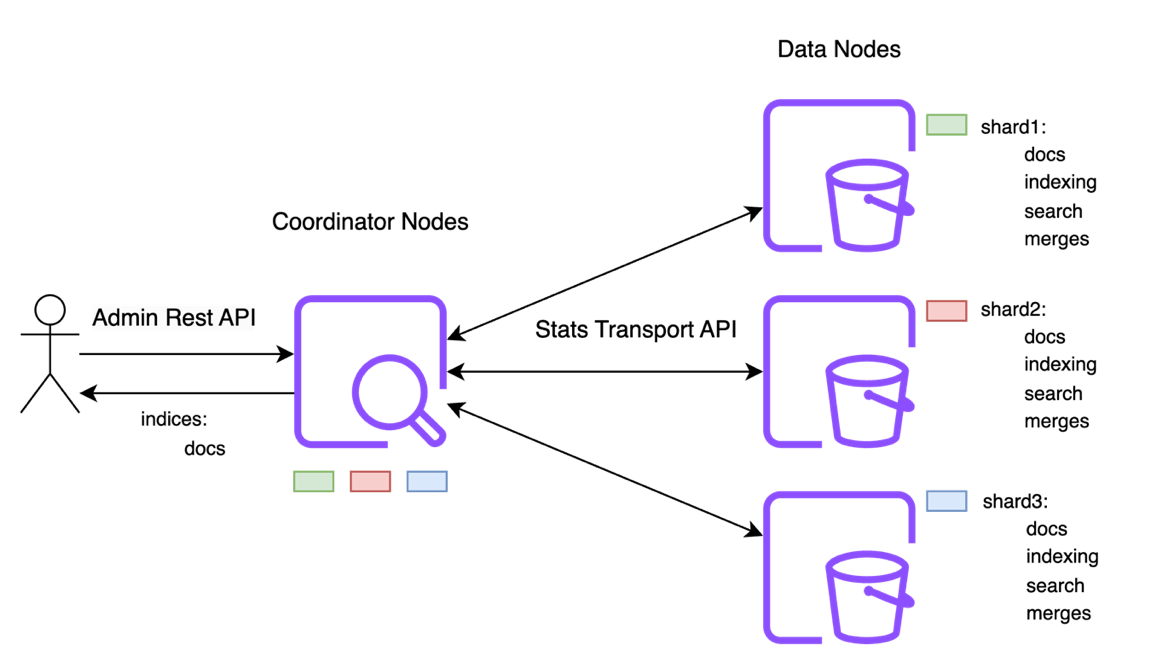
For a cluster with 500,000 shards, the coordinator node must retrieve stats responses from completely different nodes whose sizes sum to round 2.5 GB. The retrieval of such giant response sizes may cause the next points:
- Excessive community throughput quantity between nodes.
- Elevated reminiscence strain as a result of statistics responses returned by knowledge nodes are amassed in reminiscence of the coordinator node earlier than setting up the user-facing response.
The reminiscence strain may cause a circuit breaker of the coordinator node to journey, leading to 429 TOO MANY REQUEST responses. It additionally ends in a rise in CPU utilization on the coordinator node on account of rubbish assortment cycles being triggered to reclaim the heap used for stats requests. The overloading of the coordinator node to fetch statistics data for admin requests can doubtlessly lead to rejecting crucial API requests resembling well being verify, search, and indexing, leading to a spiral impact of failures.
Resolution: Native aggregation and filtering
As a result of the admin API returns solely the user-requested stats within the response, it isn’t required by knowledge nodes to ship your complete shard-level stats as a result of it’s not requested by the person. Now we have now launched stats aggregation at transport motion so every knowledge node aggregates the stats domestically after which responds again to the coordinator node. Moreover, knowledge nodes assist filtering of statistics so solely particular shard stats, as requested by the person, will be returned to the coordinator. This ends in decreased compute and reminiscence on coordinator nodes as a result of they now work with responses which might be far smaller.
The next output is the shard stats returned by a knowledge node to the coordinator node after native aggregation by index. The response can also be filtered primarily based on user-requested statistics. The response comprises solely docs and retailer metrics aggregated by index for shards current on the node.
Impression: Quicker response time
The next desk exhibits the latency for well being and stats API endpoints in a big cluster. These outcomes are for a cluster dimension of three cluster supervisor nodes, 1,000 knowledge nodes, and 500,000 shards. As defined within the following pull request, the optimization to pre-compute statistics previous to sending response helps scale back response dimension and enhance latency.
| API | Response Latency | |
| Current Setup | With Optimization | |
| _cluster/stats | 15s | 0.65s |
| _nodes/stats | 13.74s | 1.69s |
| _cluster/well being | 0.56s | 0.15s |
Bottleneck 3: Lengthy-running stats request
With admin APIs, customers can specify the timeout parameter as a part of the request. This helps the shopper fail quick if requests are taking extra time to be processed on account of an overloaded chief or knowledge node. Nevertheless, the coordinator node continues to course of the request and provoke inside transport requests to knowledge nodes even after the person’s request will get disconnected. That is wasteful work and causes pointless load on the cluster as a result of the response from the information node is discarded by the coordinator after the request has timed out. No mechanism exists for the coordinator to trace that the request has been cancelled by the person and additional downstream transport calls don’t have to be tried.
Resolution: Cancellation at transport layer
To forestall long-running transport requests for admin APIs and scale back the overhead on the already overwhelmed knowledge nodes, cancellation has been applied on the transport layer. That is now utilized by the coordinator to cancel the transport requests to knowledge nodes after the user-specified timeout expires.
Impression: Fail quick with out cascading failures
The _cat/shards API fails gracefully if the chief is overloaded in case of huge clusters. The API returns a timeout response to the person with out issuing broadcast calls to knowledge nodes.
Bottleneck 4: Large response dimension
Let’s now have a look at challenges with the favored _cat APIs. Traditionally, CAT APIs didn’t assist pagination as a result of the metadata wasn’t anticipated to develop to tens of 1000’s in dimension when it was designed. This assumption not holds for giant clusters and may trigger compute and reminiscence spikes whereas serving these APIs.
Resolution: Paginated APIs
After cautious deliberations with the neighborhood, we launched a brand new set of paginated record APIs for metadata retrieval. The APIs _list/indices and _list/shards are pagination counterparts to _cat/indices and _cat/shards. The _list APIs keep pagination stability, so {that a} paginated dataset maintains order and consistency even when a brand new index is added or an present index is eliminated. That is achieved by utilizing a mixture of index creation timestamps and index names as web page tokens.
Impression: Bounded response time
_list/shards can now efficiently return paginated responses for a cluster with 500,000 shards with out getting timed out. Fastened response sizes facilitate sooner knowledge retrieval with out overwhelming the cluster for giant datasets.
Conclusion
Admin API’s are crucial for observability and metadata administration of OpenSearch domains. Admin APIs, if not designed correctly, introduce bottlenecks within the system and impacts the efficiency of OpenSearch domains. The enhancements made for these APIs in model 2.17 have efficiency positive aspects for all clients of OpenSearch service no matter whether or not it’s large-sized (1,000 nodes), mid-sized (200 nodes), or small-sized (20 nodes). It ensures that elected cluster supervisor node is steady even when the API’s are exercised for domains with giant metadata dimension. OpenSearch is an open supply, community-driven software program. The foundational items of APIs resembling pagination, cancellation, and native aggregation are extensible and can be utilized for different APIs.
If you want to contribute to OpenSearch, open up a GitHub challenge and tell us your ideas. You possibly can get began with these open PR’s in Github [PR1] [PR2] [PR3] [PR4].
Concerning the authors