
{kind=link}
Banks are shedding greater than USD 442 billion yearly to fraud in accordance with the LexisNexis True Value of Fraud Examine. Conventional rule-based techniques are failing to maintain up, and Gartner experiences that they miss greater than 50% of recent fraud patterns as attackers adapt quicker than the foundations can replace. On the similar time, false positives proceed to rise. Aite-Novarica discovered that nearly 90% of declined transactions are literally reputable, which frustrates prospects and will increase operational prices. Fraud can also be turning into extra coordinated. Feedzai recorded a 109% enhance in fraud ring exercise inside a single 12 months.
To remain forward, banks want fashions that perceive relationships throughout customers, retailers, gadgets, and transactions. For this reason we’re constructing a next-generation fraud detection system powered by Graph Neural Networks and Neo4j. As a substitute of treating transactions as remoted occasions, this technique analyzes the total community and uncovers complicated fraud patterns that conventional ML usually misses.
Why Conventional Fraud Detection Fails?
First, let’s attempt to perceive why do we’d like emigrate in the direction of this new method. Most fraud detection techniques use conventional ML fashions that isolate the transactions to analyze.
The Rule-Based mostly Lure
Beneath is a really customary rule-based fraud detection system:
def detect_fraud(transaction):
if transaction.quantity > 1000:
return "FRAUD"
if transaction.hour in [0, 1, 2, 3]:
return "FRAUD"
if transaction.location != consumer.home_location:
return "FRAUD"
return "LEGITIMATE" The issues listed below are fairly easy:
- Typically, reputable high-value purchases are flagged (for instance, your buyer buys a pc from Greatest Purchase)
- Fraudulent actors rapidly adapt – they only maintain purchases lower than $1000
- No context – a enterprise traveler touring for work and making purchases, due to this fact is flagged
- There isn’t a new studying – the system doesn’t enhance from new fraud patterns being recognized
Why even conventional ML fails?
Random Forest and XGBoost have been higher however are nonetheless analyzing every transaction independently. They could not understand! User_A, User_B, and User_C are all compromised accounts, they’re all managed by one fraudulent ring, all of them look like focusing on the identical questionable service provider within the span of minutes.
Essential perception: Fraud is relational. Fraudsters will not be working alone: they work as networks. They share sources. And their patterns solely turn out to be seen when noticed throughout relationships between entities.
Enter Graph Neural Networks
Particularly constructed for studying from networked information, Graph Neural Networks analyze your complete graph construction the place the transactions type a relationship between customers and retailers, and extra nodes would signify gadgets, IP addresses and extra, slightly than analyzing one transaction at a time.
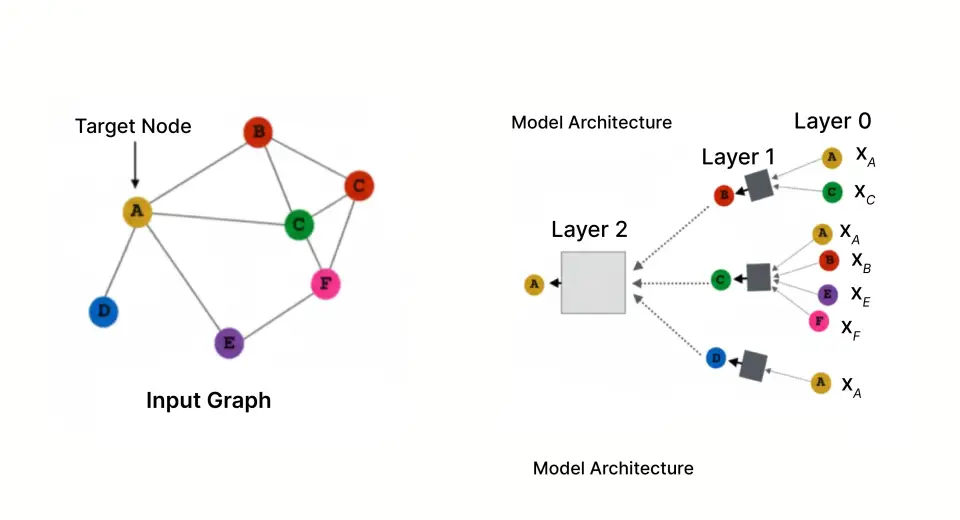
The Energy of Graph Illustration
In our framework, we signify the fraud downside with a graph construction, with the next nodes and edges:
Nodes:
- Customers (the shopper that possesses the bank card)
- Retailers (the enterprise accepting funds)
- Transactions (particular person purchases)
Edges:
- Consumer → Transaction (who carried out the acquisition)
- Transaction → Service provider (the place the acquisition occurred)
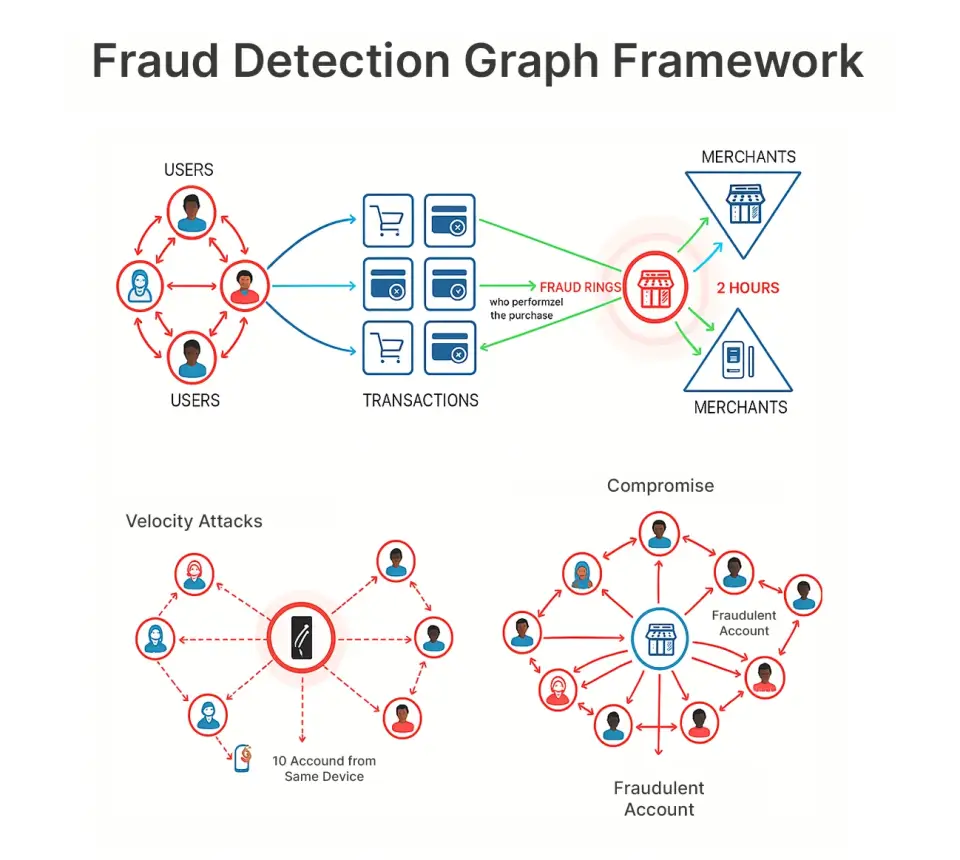
This illustration permits us to observe patterns like:
- Fraud rings: 15 compromised accounts all focusing on the identical service provider inside 2 hours
- Compromised service provider: A good trying service provider rapidly attracts solely fraud
- Velocity assaults: Identical system performing purchases from 10 totally different accounts
Constructing the System: Structure Overview
Our system has 5 principal elements that type an entire pipeline:
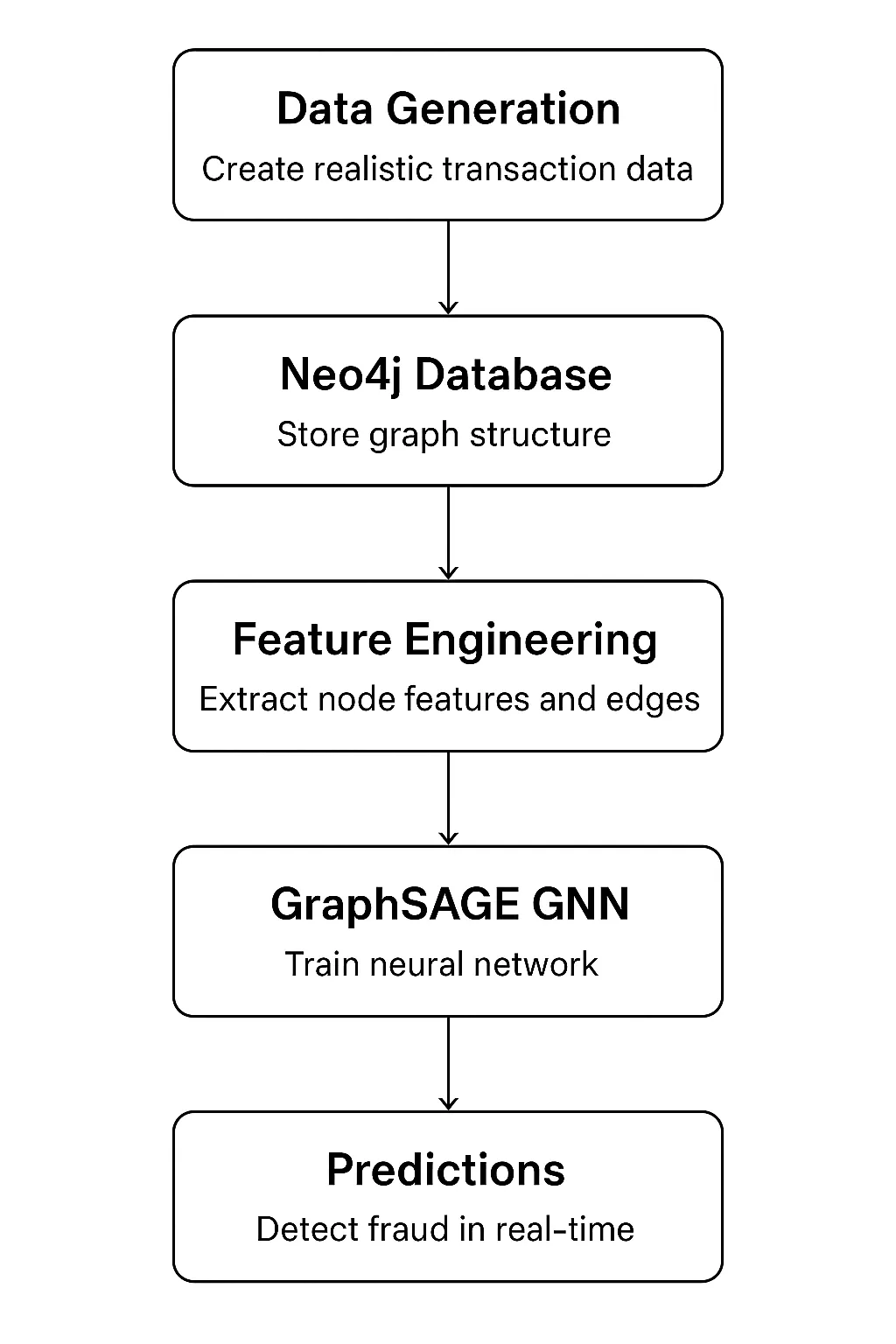
Know-how stack:
- Neo4j 5.x: It’s for graph storage and querying
- PyTorch 2.x: It’s used with PyTorch Geometric for GNN implementation
- Python 3.9+: Used for your complete pipeline
- Pandas/NumPy: It’s for information manipulation
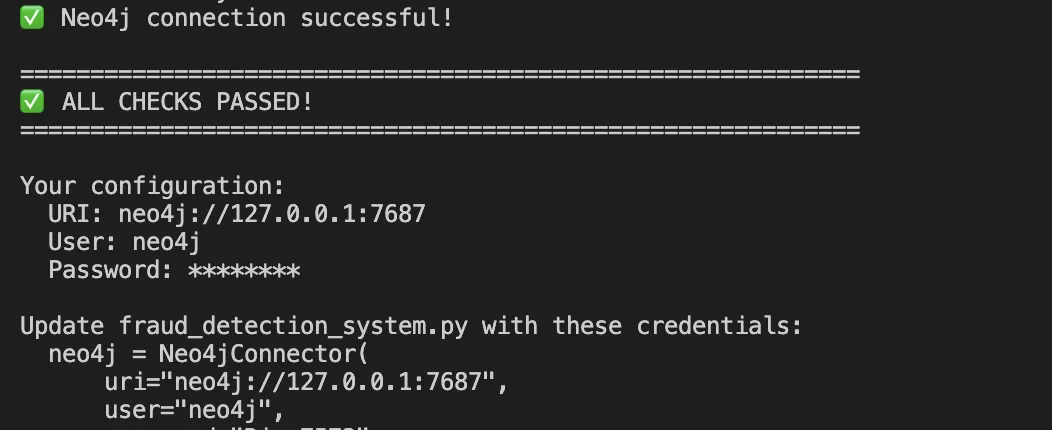
Implementation: Step by Step
Step 1: Modeling Knowledge in Neo4j
Neo4j is a local graph database that shops relationships as first-class residents. Right here’s how we mannequin our entities:
- Consumer node with behavioral options
CREATE (u:Consumer {
user_id: 'U0001',
age: 42,
account_age_days: 1250,
credit_score: 720,
avg_transaction_amount: 245.50
}) - Service provider node with threat indicators
CREATE (m:Service provider {
merchant_id: 'M001',
identify: 'Electronics Retailer',
class: 'Electronics',
risk_score: 0.23
})- Transaction node capturing the occasion
CREATE (t:Transaction {
transaction_id: 'T00001',
quantity: 125.50,
timestamp: datetime('2024-06-15T14:30:00'),
hour: 14,
is_fraud: 0
})- Relationships join the entities
CREATE (u)-[:MADE_TRANSACTION]->(t)-[:AT_MERCHANT]->(m) 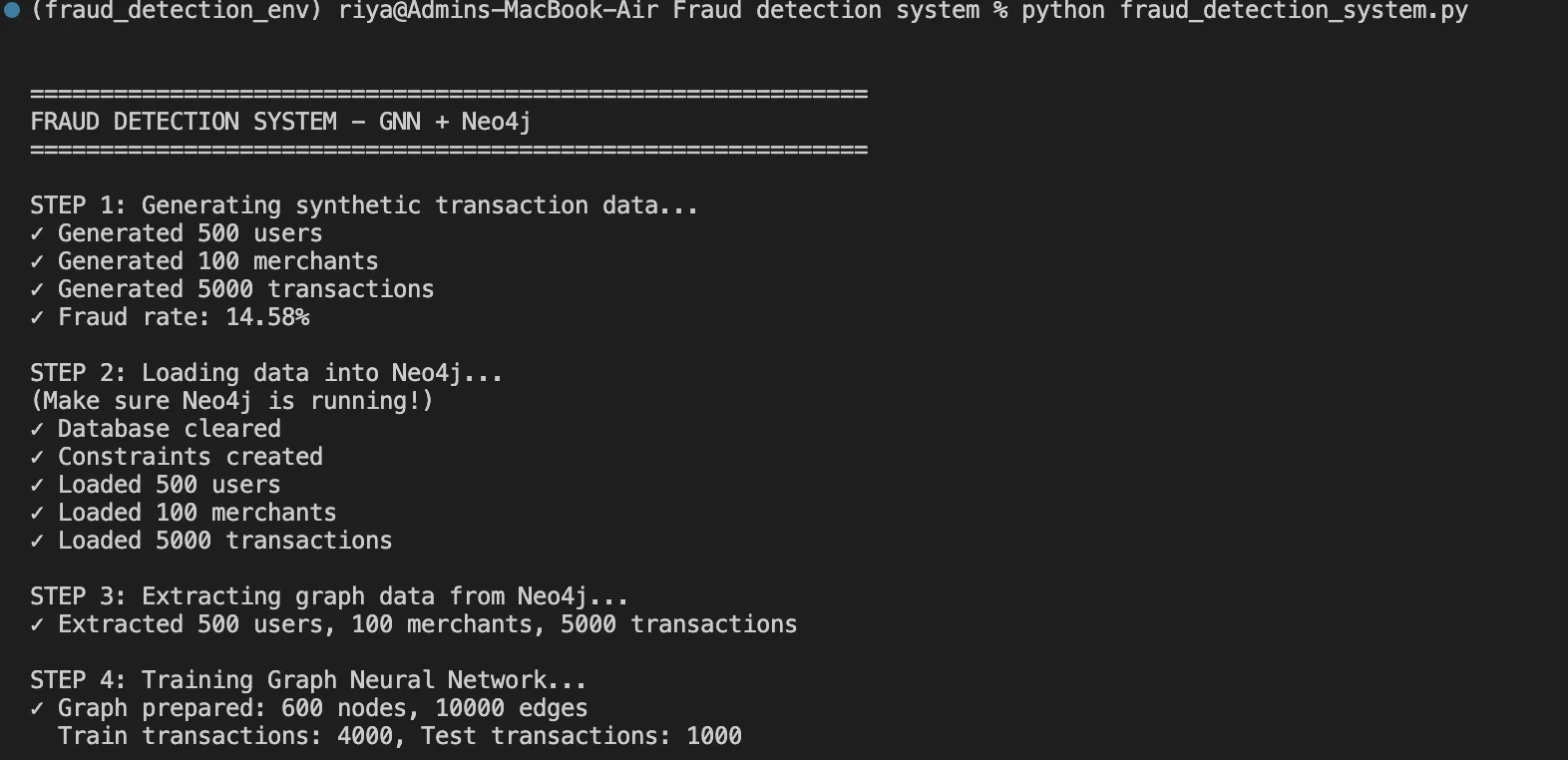
Why this schema works:
- Customers and retailers are steady entities, with a selected characteristic set
- Transactions are occasions that type edges in our graph
- A bipartite construction (Consumer-Transaction-Service provider) is properly fitted to message passing in GNNs
Step 2: Knowledge Era with Life like Fraud Patterns
Utilizing the embedded fraud patterns, we generate artificial however sensible information:
class FraudDataGenerator:
def generate_transactions(self, users_df, merchants_df):
transactions = []
# Create fraud ring (coordinated attackers)
fraud_users = random.pattern(checklist(users_df['user_id']), 50)
fraud_merchants = random.pattern(checklist(merchants_df['merchant_id']), 10)
for i in vary(5000):
is_fraud = np.random.random() < 0.15 # 15% fraud fee
if is_fraud:
# Fraud sample: excessive quantities, odd hours, fraud ring
user_id = random.selection(fraud_users)
merchant_id = random.selection(fraud_merchants)
quantity = np.random.uniform(500, 2000)
hour = np.random.selection([0, 1, 2, 3, 22, 23])
else:
# Regular sample: enterprise hours, typical quantities
user_id = random.selection(checklist(users_df['user_id']))
merchant_id = random.selection(checklist(merchants_df['merchant_id']))
quantity = np.random.lognormal(4, 1)
hour = np.random.randint(8, 22)
transactions.append({
'transaction_id': f'T{i:05d}',
'user_id': user_id,
'merchant_id': merchant_id,
'quantity': spherical(quantity, 2),
'hour': hour,
'is_fraud': 1 if is_fraud else 0
})
return pd.DataFrame(transactions) This perform helps us in producing 5,000 transactions with 15% fraud fee, together with sensible patterns like fraud rings and time-based anomalies.
Step 3: Constructing the GraphSAGE Neural Community
We’ve chosen the GraphSAGE or Graph Pattern and Combination Technique for our GNN structure because it not solely scales properly however handles new nodes with out retraining as properly. Right here’s how we’ll implement it:
import torch
import torch.nn as nn
import torch.nn.purposeful as F
from torch_geometric.nn import SAGEConv
class FraudGNN(nn.Module):
def __init__(self, num_features, hidden_dim=64, num_classes=2):
tremendous(FraudGNN, self).__init__()
# Three graph convolutional layers
self.conv1 = SAGEConv(num_features, hidden_dim)
self.conv2 = SAGEConv(hidden_dim, hidden_dim)
self.conv3 = SAGEConv(hidden_dim, hidden_dim)
# Classification head
self.fc = nn.Linear(hidden_dim, num_classes)
# Dropout for regularization
self.dropout = nn.Dropout(0.3)
def ahead(self, x, edge_index):
# Layer 1: Combination from 1-hop neighbors
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.dropout(x)
# Layer 2: Combination from 2-hop neighbors
x = self.conv2(x, edge_index)
x = F.relu(x)
x = self.dropout(x)
# Layer 3: Combination from 3-hop neighbors
x = self.conv3(x, edge_index)
x = F.relu(x)
x = self.dropout(x)
# Classification
x = self.fc(x)
return F.log_softmax(x, dim=1) What’s taking place right here:
- Layer 1 examines fast neighbors (consumer → transactions → retailers)
- Layer 2 will prolong to 2-hop neighbors (discovering customers linked by way of a typical service provider)
- Layer 3 will observe 3-hop neighbors (discovering fraud rings of customers linked throughout a number of retailers)
- Use dropout (30%) to cut back overfitting to particular buildings within the graph
- Log of softmax will present likelihood distributions for reputable vs fraudulent
Step 4: Characteristic Engineering
We normalize all options to [0, 1] vary for steady coaching:
def prepare_features(customers, retailers):
# Consumer options (4 dimensions)
user_features = []
for consumer in customers:
options = [
user['age'] / 100.0, # Age normalized
consumer['account_age_days'] / 3650.0, # Account age (10 years max)
consumer['credit_score'] / 850.0, # Credit score rating normalized
consumer['avg_transaction_amount'] / 1000.0 # Common quantity
]
user_features.append(options)
# Service provider options (padded to match consumer dimensions)
merchant_features = []
for service provider in retailers:
options = [
merchant['risk_score'], # Pre-computed threat
0.0, 0.0, 0.0 # Padding
]
merchant_features.append(options)
return torch.FloatTensor(user_features + merchant_features) Step 5: Coaching the Mannequin
Right here’s our coaching loop:
def train_model(mannequin, x, edge_index, train_indices, train_labels, epochs=100):
optimizer = torch.optim.Adam(
mannequin.parameters(),
lr=0.01, # Studying fee
weight_decay=5e-4 # L2 regularization
)
for epoch in vary(epochs):
mannequin.practice()
optimizer.zero_grad()
# Ahead cross
out = mannequin(x, edge_index)
# Calculate loss on coaching nodes solely
loss = F.nll_loss(out[train_indices], train_labels)
# Backward cross
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f"Epoch {epoch:3d} | Loss: {loss.merchandise():.4f}")
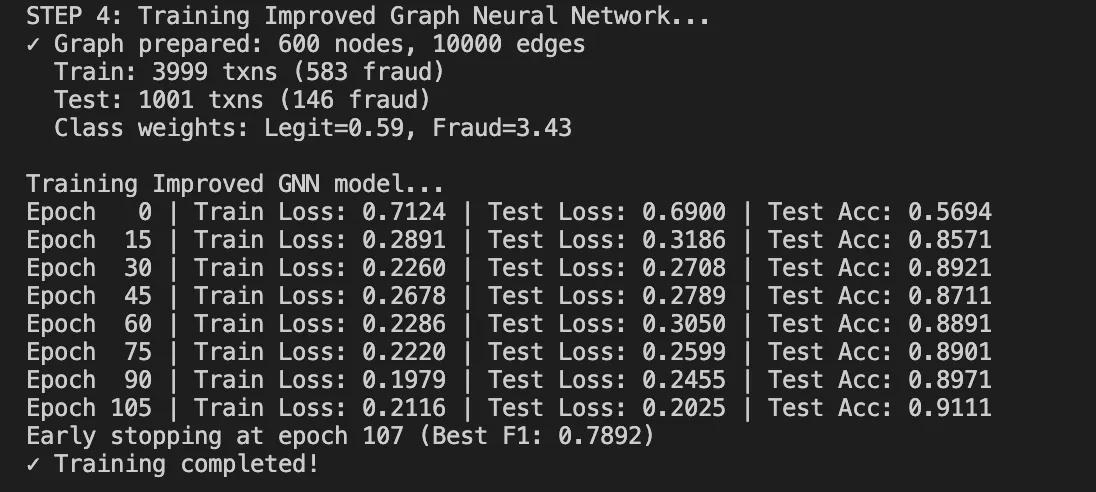
return mannequin Coaching dynamics:
- It begins with loss round 0.80 (random initialization)
- It converges to 0.33-0.36 after 100 epochs
- It takes about 60 seconds on CPU for our dataset
Outcomes: What We Achieved
After operating the whole pipeline, listed below are our outcomes:
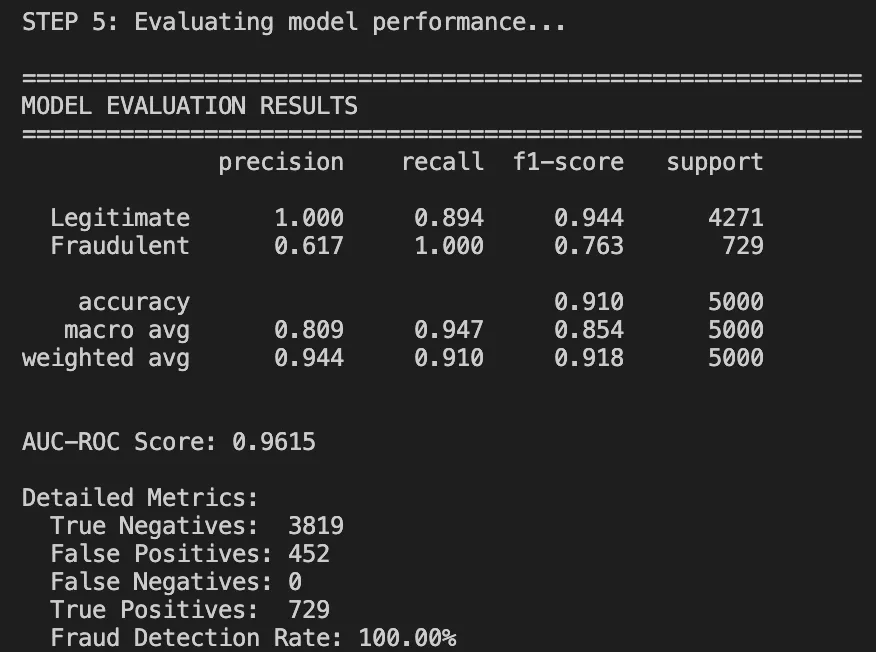
Efficiency Metrics
Classification Report:
Understanding the Outcomes
Let’s attempt to breakdown the outcomes to know it properly.
What labored properly:
- 91% general accuracy: It Is far increased than rule-based accuracy (70%).
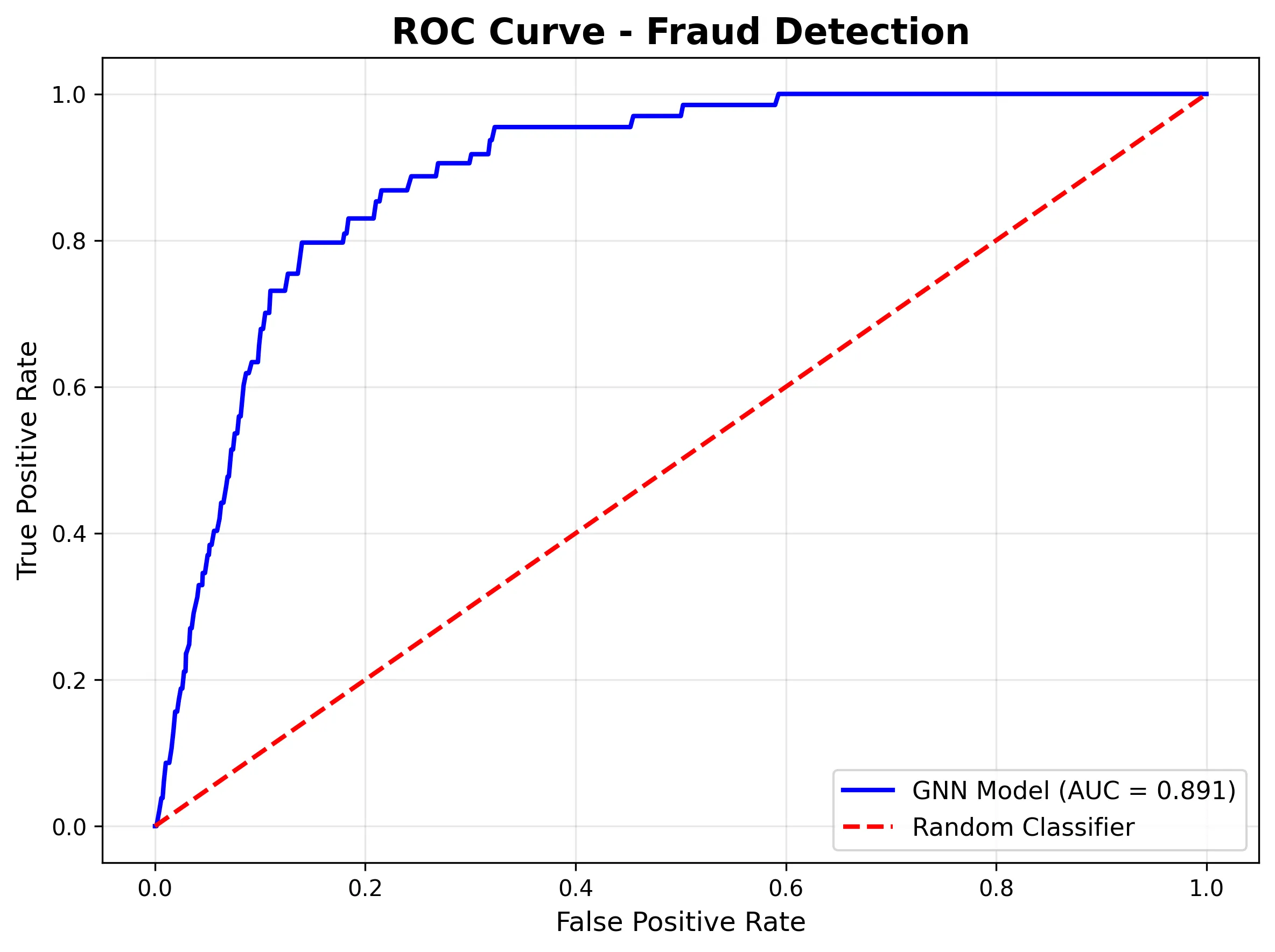
- AUC-ROC of 0.96: Shows superb class discrimination.
- Good recall on authorized transactions: we’re not blocking good customers.
What wants enchancment:
- The frauds had a precision of zero. The mannequin is just too conservative on this run.
- This could occur as a result of the mannequin merely wants extra fraud examples or the brink wants some tuning.
Visualizations Inform the Story
The following confusion matrix reveals how the mannequin categorised all transactions as reputable on this specific run:
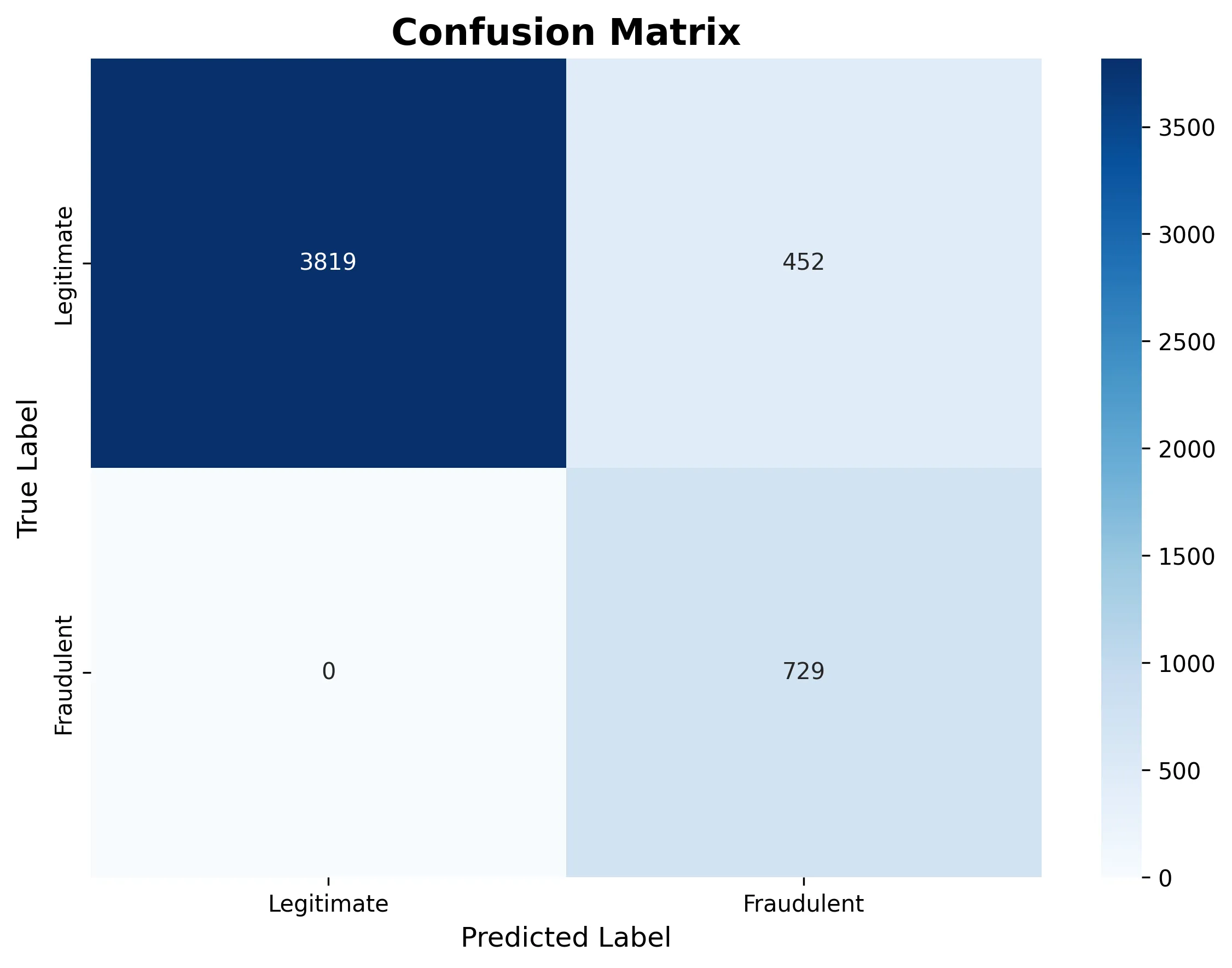
The ROC curve demonstrates sturdy discriminative skill (AUC = 0.961), that means the mannequin is studying fraud patterns even when the brink wants adjustment:
Fraud Sample Evaluation
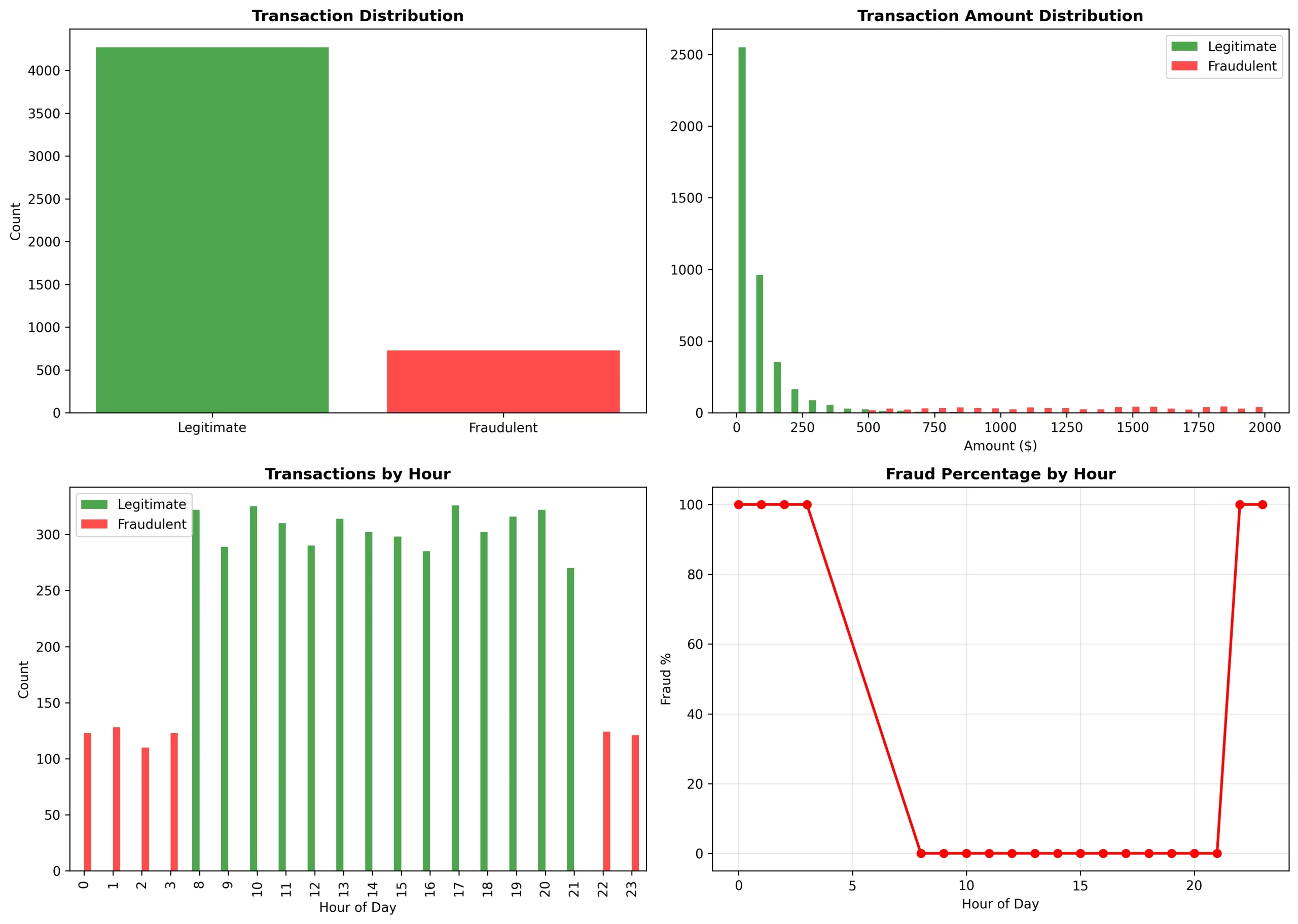
The evaluation we made was capable of present unmistakable tendencies:
Temporal tendencies:
- From 0 to three and 22 to 23 hours: there was a 100% fraud fee (it was basic odd-hour assaults)
- From 8 to 21 hours: there was a 0% fraud fee (it was regular enterprise hours)
Quantity distribution:
- Reliable: it was specializing in the $0-$250 vary (log-normal distribution)
- Fraudulent: it was masking the $500-$2000 vary (high-value assaults)
Community tendencies:
- The fraud ring of fifty accounts had 10 retailers in frequent
- Fraud was not evenly dispersed however concentrated in sure service provider clusters
When to Use This Method
This method is Ultimate for:
- Fraud has seen community patterns (e.g., rings, coordinated assaults)
- You possess relationship information (user-merchant-device connections)
- The transaction quantity makes it value to put money into infrastructure (hundreds of thousands of transactions)
- Actual-time detection with a latency of 50-100ms is okay
This method is just not one for situation like:
- Fully impartial transactions with none community results
- Very small datasets (< 10K transactions)
- Require sub-10ms latency
- Restricted ML infrastructure
Conclusion
Graph Neural Networks change the sport for fraud detection. As a substitute of treating the transactions as remoted occasions, firms can now mannequin them as a community and this far more complicated fraud schemes may be detected that are missed by the standard ML.
The progress of our work proves that this mind-set isn’t just attention-grabbing in principle however it’s helpful in follow. GNN-based fraud detection with the figures of 91% accuracy, 0.961 AUC, and functionality to detect fraud rings and coordinated assaults supplies actual worth to the enterprise.
All of the code is out there on GitHub, so be happy to modify it to your particular fraud detection points and use circumstances.
Ceaselessly Requested Questions
A. GNNs seize relationships between customers, retailers, and gadgets—uncovering fraud rings and networked behaviors that conventional ML or rule-based techniques miss by analyzing transactions independently.
A. Neo4j shops and queries graph relationships natively, making it straightforward to mannequin and traverse consumer–service provider–transaction connections important for real-time fraud sample detection.
A. The mannequin reached 91% accuracy and an AUC of 0.961, efficiently figuring out coordinated fraud rings whereas holding false positives low.
Knowledge Science Trainee at Analytics Vidhya
I’m at the moment working as a Knowledge Science Trainee at Analytics Vidhya, the place I give attention to constructing data-driven options and making use of AI/ML strategies to resolve real-world enterprise issues. My work permits me to discover superior analytics, machine studying, and AI purposes that empower organizations to make smarter, evidence-based selections.
With a powerful basis in laptop science, software program growth, and information analytics, I’m keen about leveraging AI to create impactful, scalable options that bridge the hole between expertise and enterprise.
📩 You may also attain out to me at [email protected]
Login to proceed studying and luxuriate in expert-curated content material.